CLIP 相关工作1
1. Language-driven Semantic Segmentation
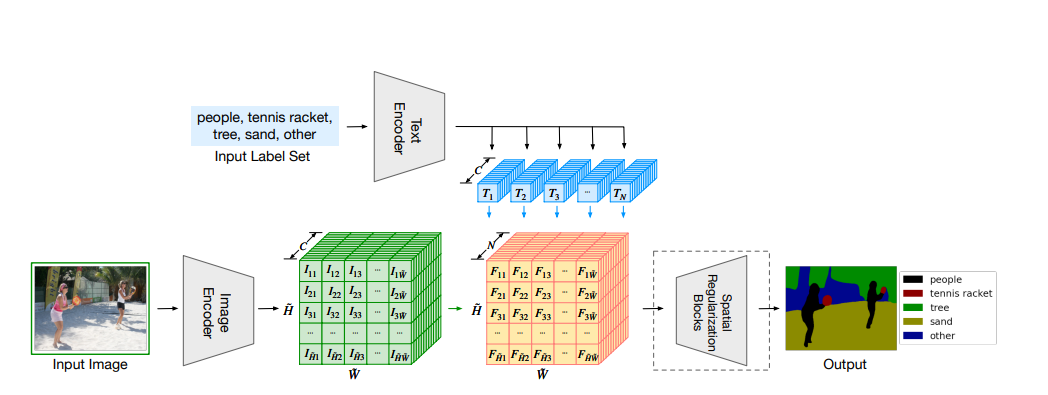
First, using clip text encoder to get N tokens, each has C dimensional features. Use a pretrained image encoder (like ViT) to get H’ X W’ image tokens with each also having C dimensional features. Then by matrix multiplication, we get a HW X N matrix representing the correlations between each pixel and the text. The image encoder is then fine-tuned to maximize the correlation between the text embedding and the image pixel embedding of the ground-truth class of the pixel.
During testing, zero-shot can be done by also calculating the similarities between pixel embedding and each of the text embedding, just like CLIP.
2. GroupViT: Semantic Segmentations Emerges from Text Supervision
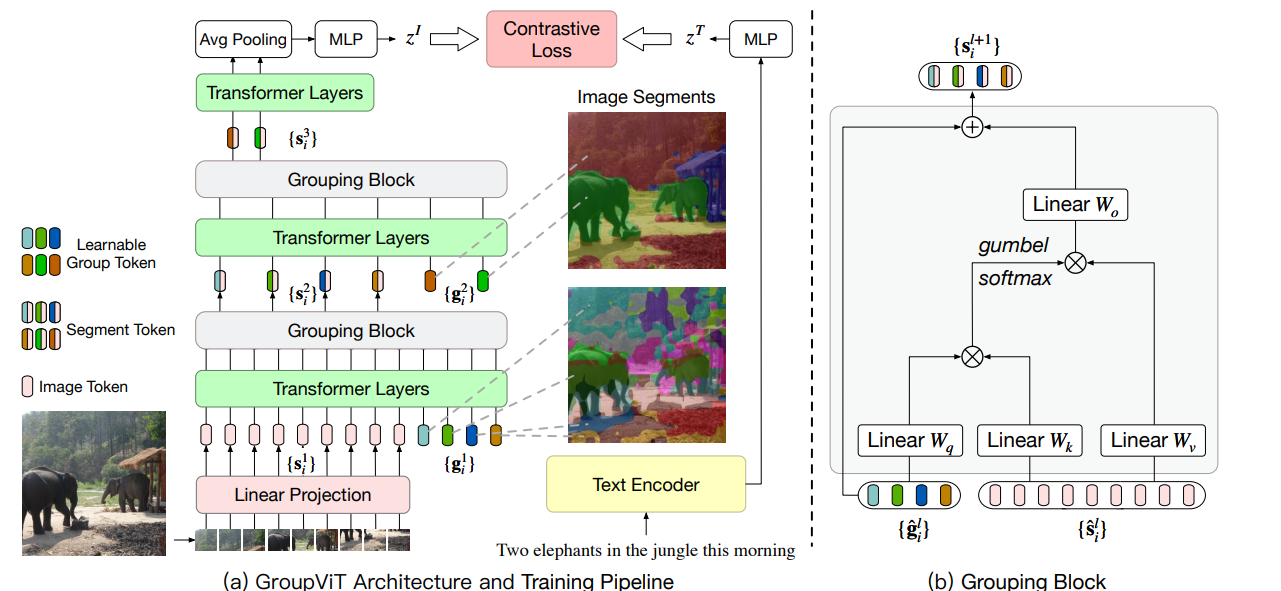
Image is fed to patch tokenizer to get N tokens, along with them, there are G1 learnable tokens representing G1 semantic groups. After several layers of Transformer blocks, using grouping block to reduce the number of tokens from N + G1 to G1. Then there are another G2 learnable semantic groups that might have higher-level semantic meanings, repeating the process, to get G2 tokens in the final output. After a avg pooling and MLP, we get a single token that can be used to calculate the contrastive loss with the text embedding from clip. Negative pairs can be generated by using unmatched text. This is training.
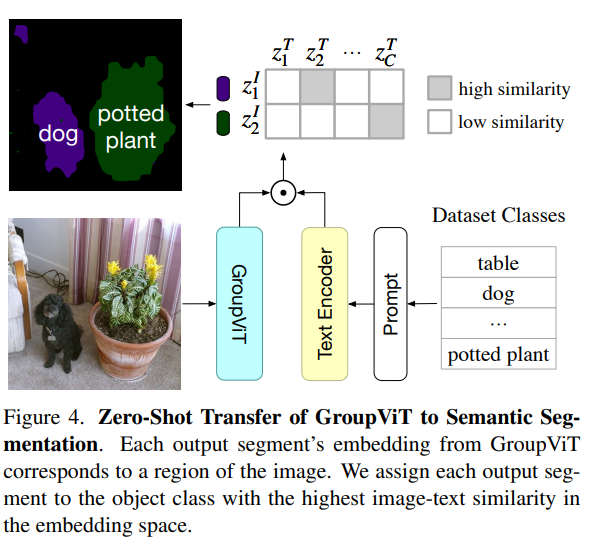
During testing, we use the final G2 tokens and compute their similarities to each class label text embedding. Use a threshold to extract those tokens, therefore the corresponding pixels in the original image as the segmented area.
3. Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
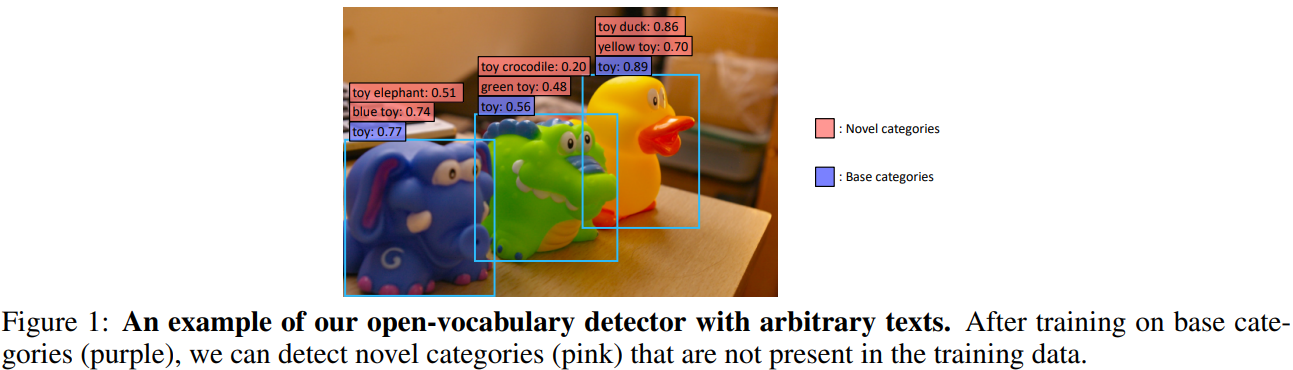
以上是要解决的问题。
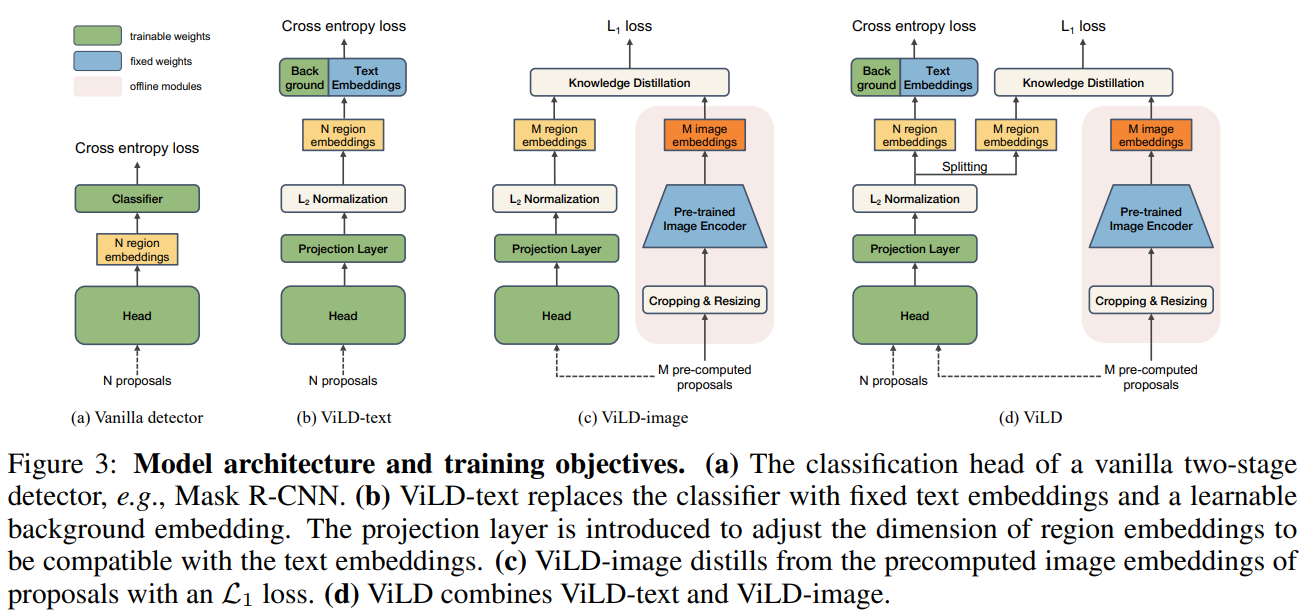
All these framworks are based on region proposals (e.g., from RPN, ROI align, etc.), then in ViLD-text, we get N region embeddings from the N proposals, then each proposal has a GT label (basic label), which can have a text embedding from clip. Additionally there is a background text embedding which is learnt. Then use the contrastive loss to train the region encoder.
In ViLD-image, because the dataset is huge, and generating N proposals from each image during training is not that feasible, so we pre-computed M proposals according to the whole dataest. Use clip image encoder to get M image embeddings, which can be a teacher to guide the training of the image encoder in the model, simply with L1 loss.
In ViLD, both knowledge distillation from clip image encoder and contrastive loss from clip text encoder are used, by simply feeding N + M proposals to the transformer and split them into N and M embeddings which are separately used to calculate the two losses.
During testing, novel labels can have corresponding regions in the image, using the same mechnism as in CLIP.
4. Grounded Language-Image Pre-Training (GLIP)
Use image grouding dataset, which also has bounding box annotations, to train a image region encoder that miminize the contrastive loss between region embeddings and text embeddings, just like ViLD-text. Then it uses the trained model to generate bounding boxes (noisy lables) for more (24M) image-text pairs and use these generatel lables to train a larger model.
The large model GLIP-T uses Swin-L.