多模态学习相关工作1
ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
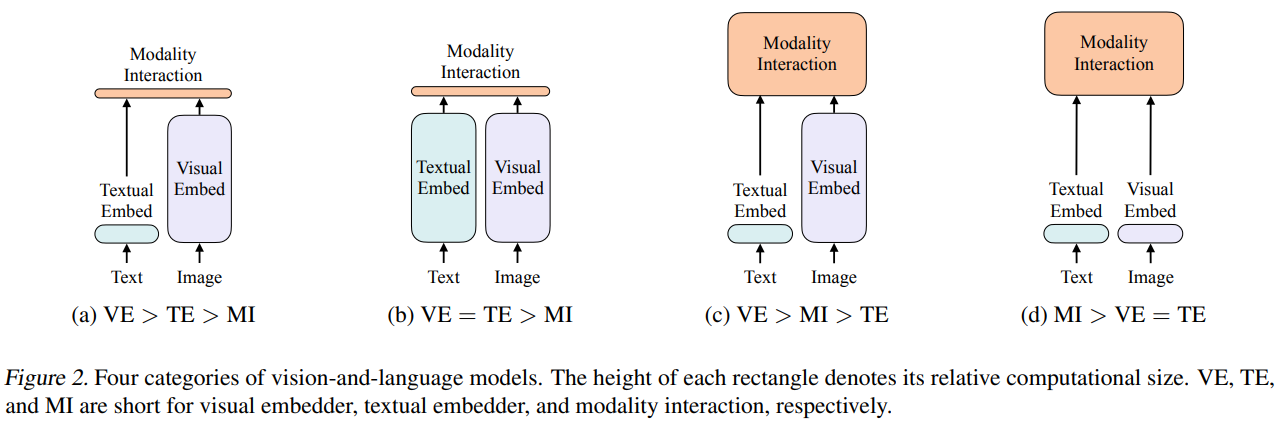
The paper summarizes four types of vision-language learning frameworks. In computer vision, it is widely accepted that visual embedder or encoder is more important than text embedder, therefore having more computational complexity.
In a), earlier works use separate embedders with light textual embedder but heavier visual embedder, and the intreaction module is just to calculate similarities between two modalities.
In b), typical work is CLIP, where two embedders are both heavy but in the intreaction, they also compute the similarity to calculate contrastive loss.
In c), paper like ViLBERT and UNITER use this frame.
In d), this is waht ViLT proposes. Just like what ViT did, they think the image embedder can be just a simple patch tokenizer. The previous three frameworks is very time-consuming when dealing with images, but ViLT demonstrates that d) can speed up maganitudes of times and still get good results.
Align before Fuse: Vision and Language Representation Learning with Momentum Distillation
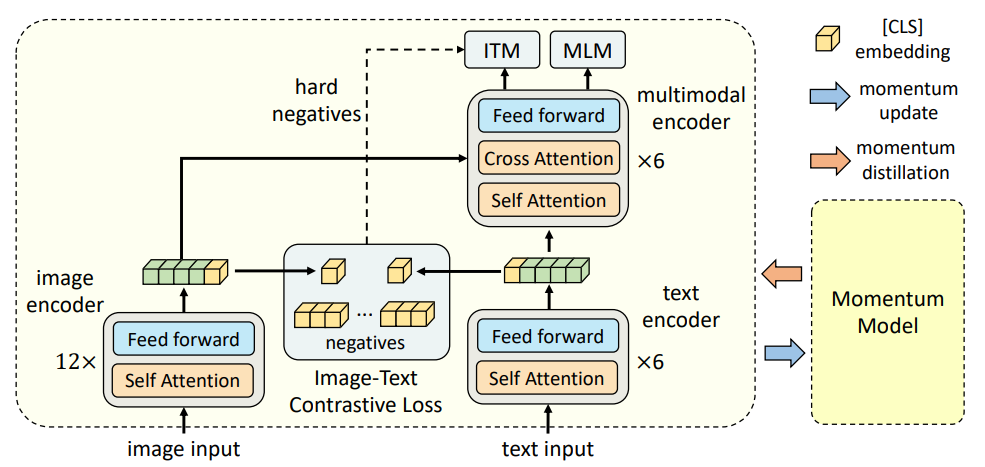
- ITC loss (image-text contrastive loss): they propose to do contrastive learning before multimodal interaction, such that the features fed to intreaction are aligned to make interaction more effective. The loss is the same as that in CLIP.
- ITM loss (image-text matching loss): use the output of the multimodal encoder to generate the classifying logits for a binary classification problem, to check whether the image-text pair is positive or negative. Here, they use the similarity scores from ITC to mine the hard negative pairs.
- MLM loss (masked language modeling loss): just like BERT, the multimodal encoder will generate textual outputs/tokens and give probability in the masked place for predicting the masked word. But this time both textual and visual information are considered for MLM via the multimodal encoder.
They also propose a momentum model for knowledge distillation for ITC and MLM losses. Like MoCov1, the moemtum model is updated based on the textual and visual embedders using the large momentum, then the moemntum model is used as a teacher model to generate similarities between images and texts as a second GT to guide ITC (it mean ITC considre both the one-hot GT and the outputs from teacher).
Similarly, the probabilities generated using teacher model for MLM is also a second GT for MLM loss.
VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
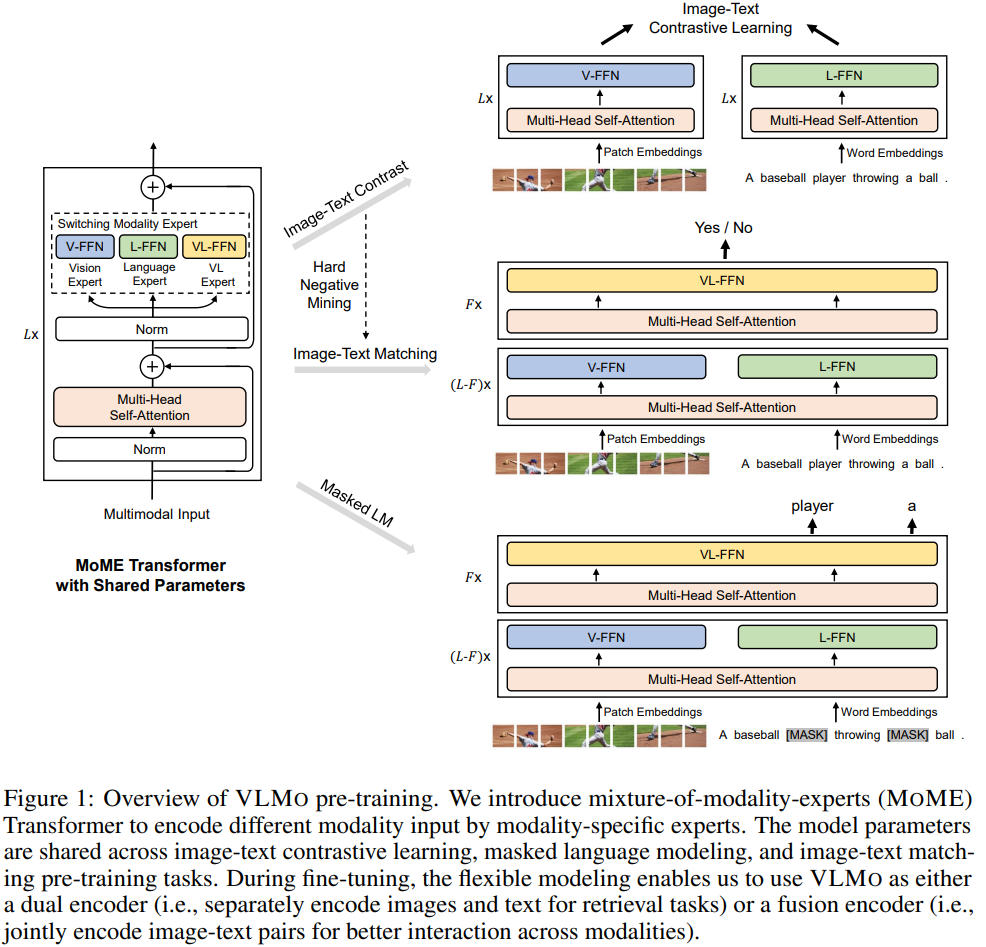
The motivation is in previous works the model cann’t do both single-modal and multi-modal tasks. For example, separately encode images and texts for retrieval tasks are singel-modal based.
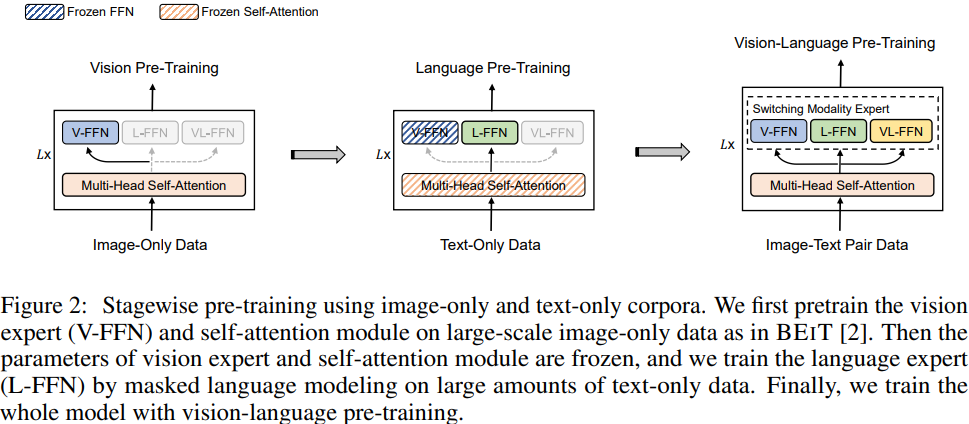
They use a multi-stage traing method, to make full use of the single-modal data (unlabeled) and the image-text pairs data. As shown in the figure, in each stage, some parameters are frozen.
So one advanntage of VLMo is that they use only one transformer architecture but separate light experts.