多模态学习相关工作2
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
The paper has two main controbituions, one is to use a decoder to caption the image, this is what previous works didn’t do since they only use transformer encoders. The other is use the trained BLIP to augment datasets. Particularly, they generate synthesized captions, then use caption filters to filter out those wrong image-text pairs. Finally, they obtain a larger scale dataset and get back to train the model again.
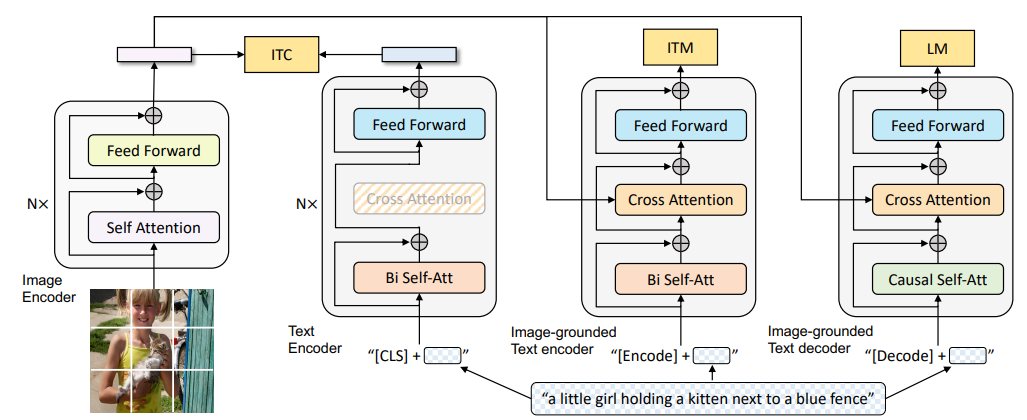
During training, they use three losses like ALBEF, but replace the MLM loss to LM (language modeling) loss to predict next word like in original Transformer. In addition, the parameters (the same color in the figure indicates the shared structure parameters) are shared when training with different losses. The causal self-att is actually using decoders.
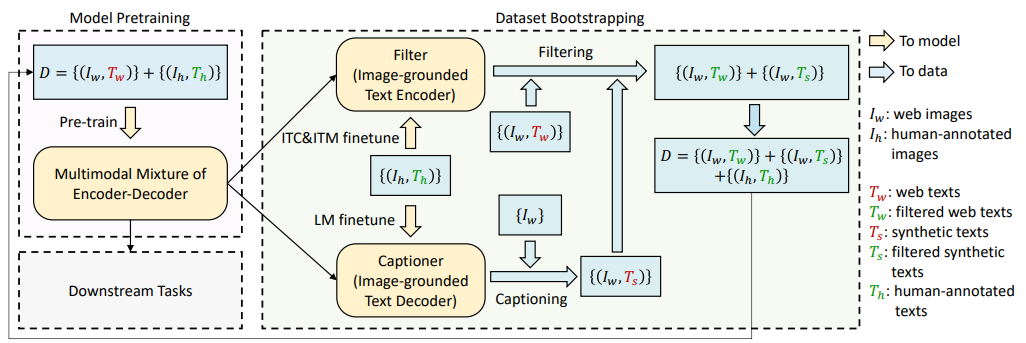
To augment data, here, {Ih, Th} are the created image-text pairs, and those green colors mean the corrected or filtered captions.
BLIP can be used in my tasks including single modal-based ones and multi-modal-based ones like question answering, because they have single-modal encoders and modal interaction embedders, and also decoders.
CoCa: Contrastive Captioners are Image-Text Foundation Models
The drawbacks of BLIP and many other methods like VLMo, ALBEF are that they need to inference the language encoders as many times as the number of losses, because each losses may use different language inputs. For example, MLM need the words to be masked.
Hence, CoCa proposes to only inference the encoder once during training.
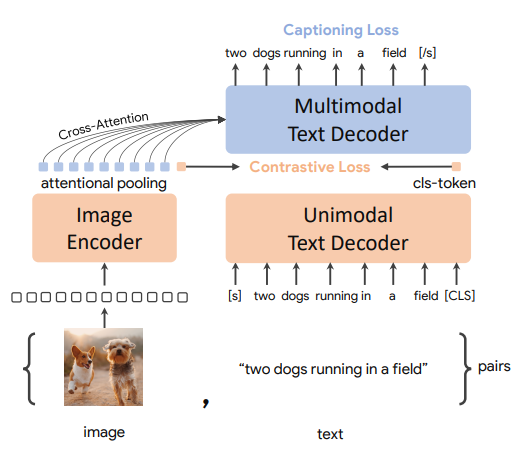
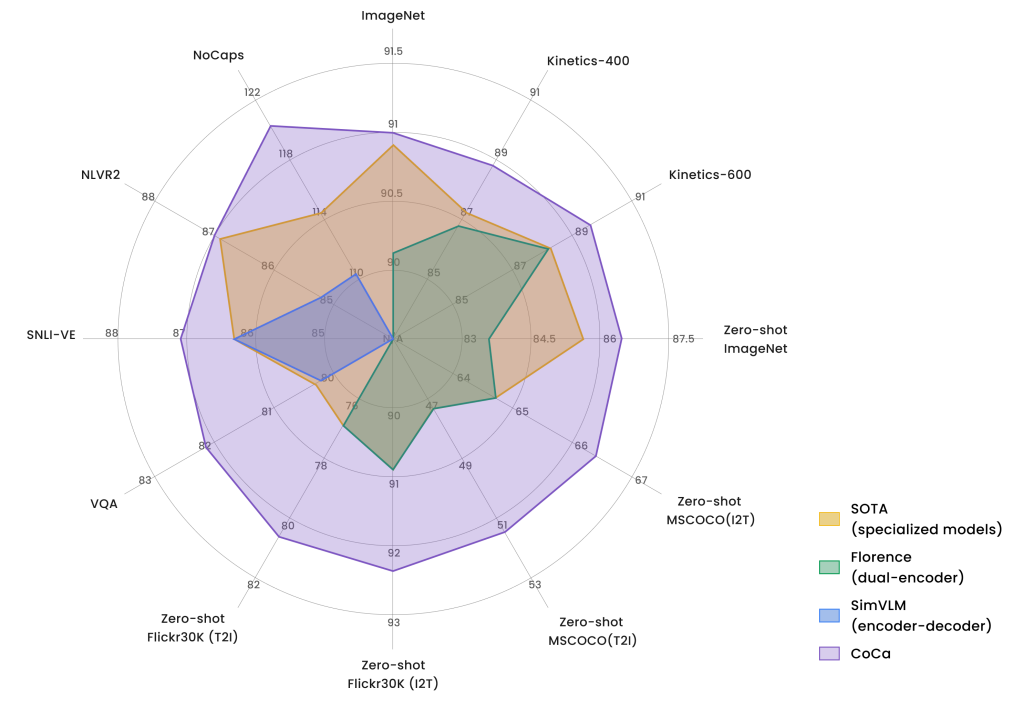
It has the ICT loss and ML loss, but the textual embedder is a transformer decoder where casual mask attention is used. The representation of text is from the last cls-token of the decoder which can see all the words in the text. The performance of CoCa is amazing!
BEiTv3: Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
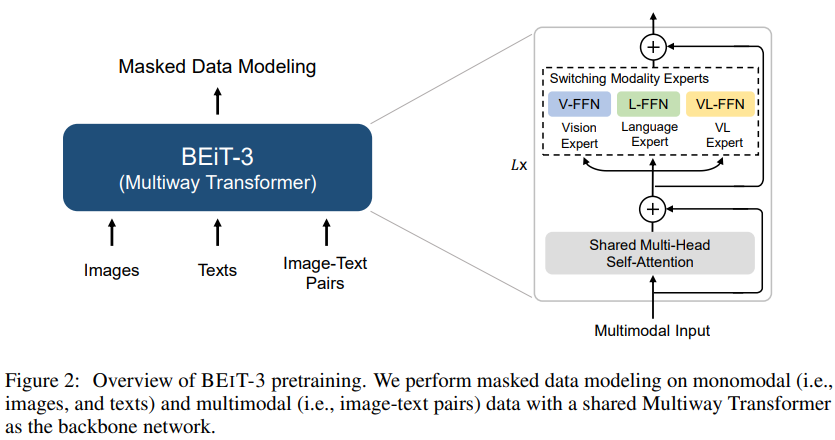
The framework is even simpler. They treat image as language (Imaglish) and the shared self-attention blocks are trained only using masked data modeling loss. For language, the loss is MLM like in BERT/ALBEF/VLMo, for image, the loss is like in MAE, for multi-modal data, I guess is also to predict the language word/image patch based on multimodal input.
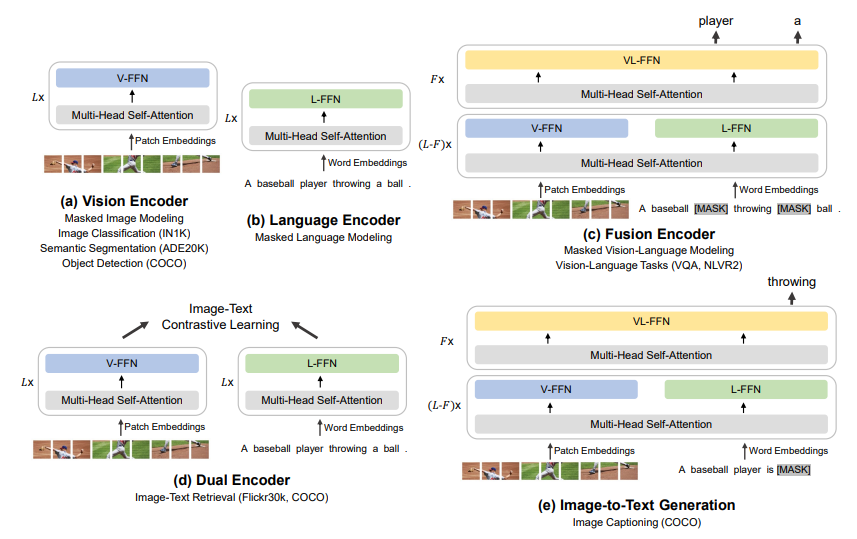
They can tasks like listed above. The performance beats that of CoCa.