InstructGPT-RLHF
Training language models to follow instructions with human feedback
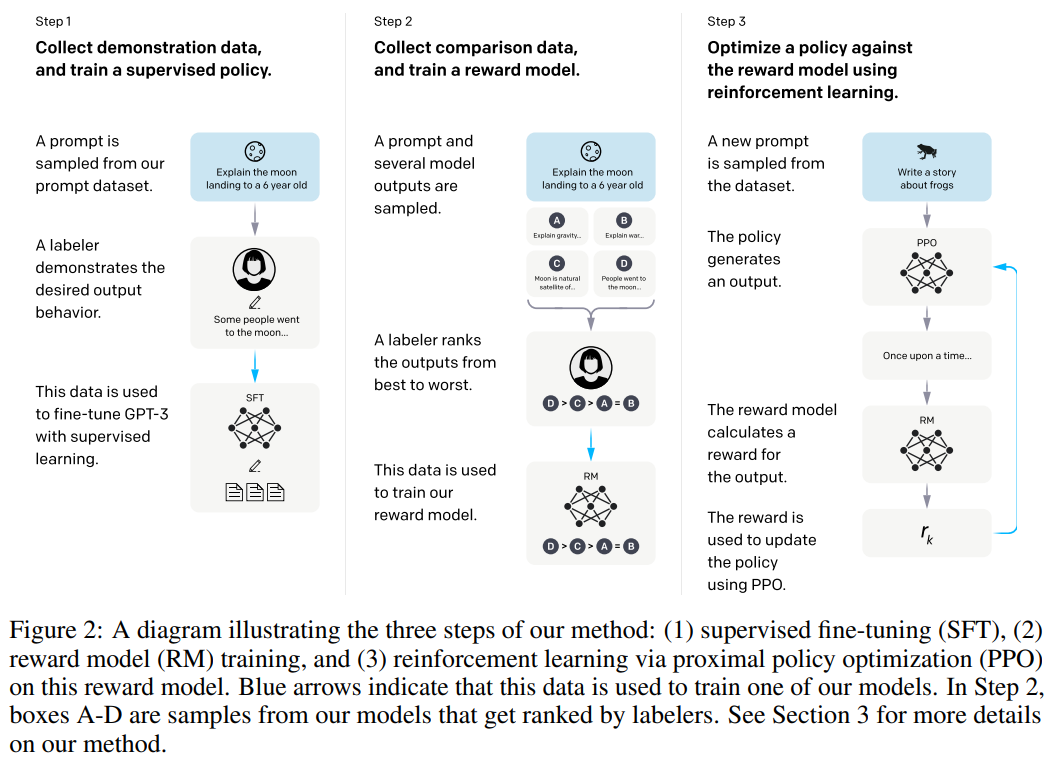
The motivation is that the output of GPT series are not aligned with the user needs, since the pre-text task in GPT is to predict next word, but the expectation of ChatGPT is to be useful and helpful for users. Thus, the authors give a 3-stage framework to fine-tune GPT-3.
First, they collect some prompts (questions) and answers from users/labelers, and use these to fine-tune GPT-3.
Second, they ask labelers to rank the multiple outputs of the model from step 1 for a single prompt. Then they train a reward model to match the ranking.
Third, they further train the model from step 1 such that its output has a high score from the reward model from step 2.
It is called reinforcement learning from human feedback, or RLHF.