Segment Anything Model (SAM)
Tutorial: https://www.youtube.com/watch?v=eYhvJR4zFUM
Segment Anything
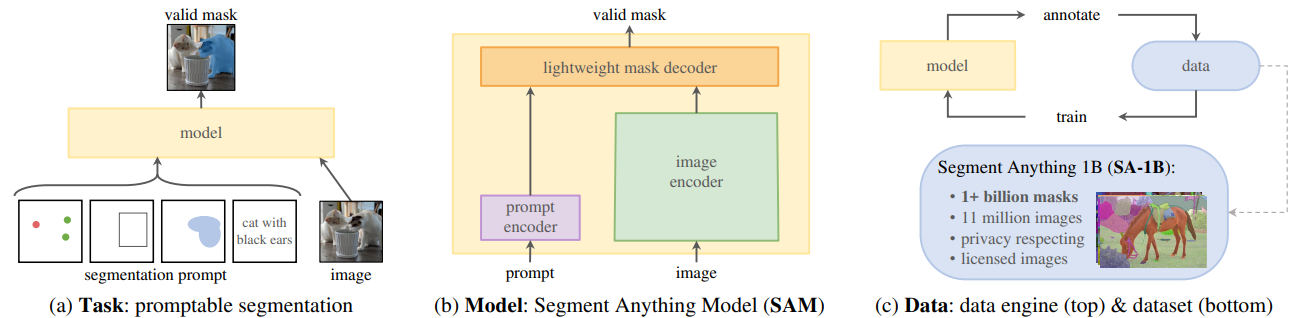
The above figure show three most important characters of the model.
- The segmentation can be prompted by four types, point, bounding box, a coarse mask, and text.
- Use a heavy image encoder to ensure the high-quality feature representation, while use a lightweight decoder to do real-time interactive segmentations depending on users’ prompts.
- Like BLIP (but not exactly the same), after a first stage training (by using annotated data), finally the model is able to generate annotations (masks) for new images without human interference, hence creating a large scale dataset with 11 million images and 1+ billion masks and go back to train the model again. It should be noted that the initial annotations generated by the model will post-processed by techniques like NMS, threshold selection, etc. Based on that, I think it makes sense to use the generated annotations to back train the model.

The model looks like this. It supports four types of prompts, therefore it has corresponding different prompt encoders to convert the prompts to tokens that can do cross-attention with the tokens from the image. The lightweight decoder will generate three mask tokens which then give three masks. The three masks deal with the problem of ambiguity from the prompts. For example, a point can associate with different objects that have the same point included.
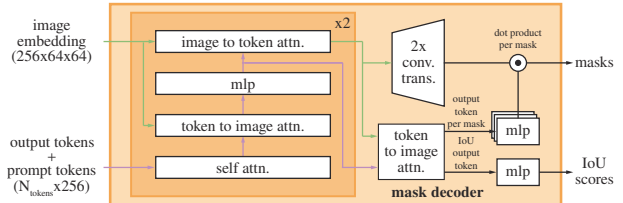
This is the details of the decoder. The output tokens (in code, they have 4 output tokens) are actually the output of the first attention blcok (there are two attention blocks), which is firtly an initialized learnable tokens, then the second attention block use the output tokens to generate 3 masks and 1 IoU score.