LLaMA - Google released on Feb 2023
tutorial: https://www.youtube.com/watch?v=Mn_9W1nCFLo&t=27s
LLaMA: Open and Efficient Foundation Language Models
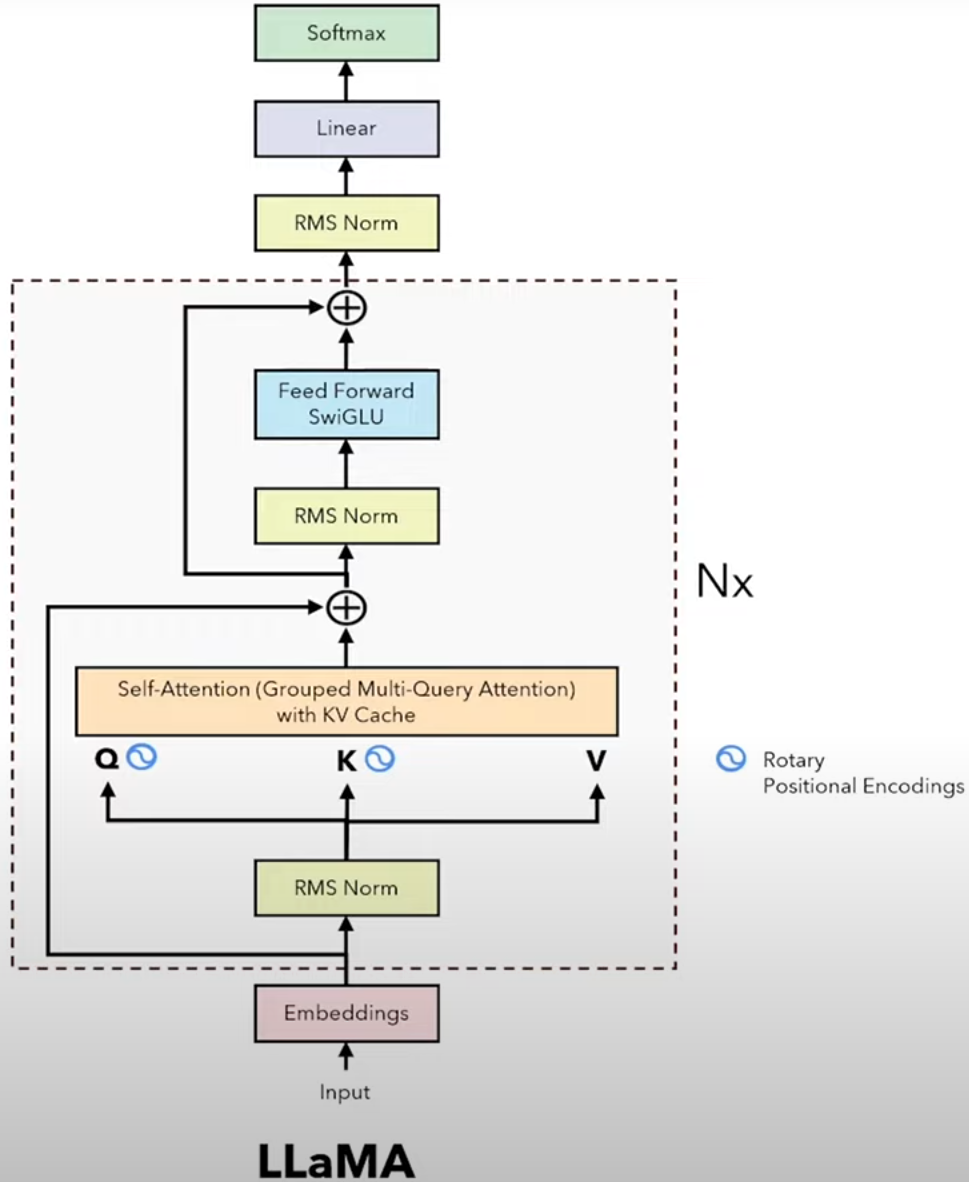
This is the framework drawn by Umar from his video tutorial. There are several concepts from LLaMa.
-
Rotary positional embedding [1]
It was proposed by Jianlin Su et al. In the origninal method that uses absolute positional embeddings, the positional embeddings are added to the feature embeddings. In the methods using relative positional embeddings, the positional embeddings are also added to the dot product of Q and K. However, they think that they can integrate the relative distance of two tokens into the dot product, or generally the inner product of Q and K. Baased on that, they define a new inner product on the complex space where the relative distance or positions can be represented by a rotation operation. -
RMS Norm (Root Mean Square Normalization) [2]
It was suggested that the stability of the training is mostly attributed to the re-scaling of variance rather than the re-centering using means. Therefore, they only focus on variance and save the computation. The network will still achieve the same effect as Layer Norm.

-
KV Cache
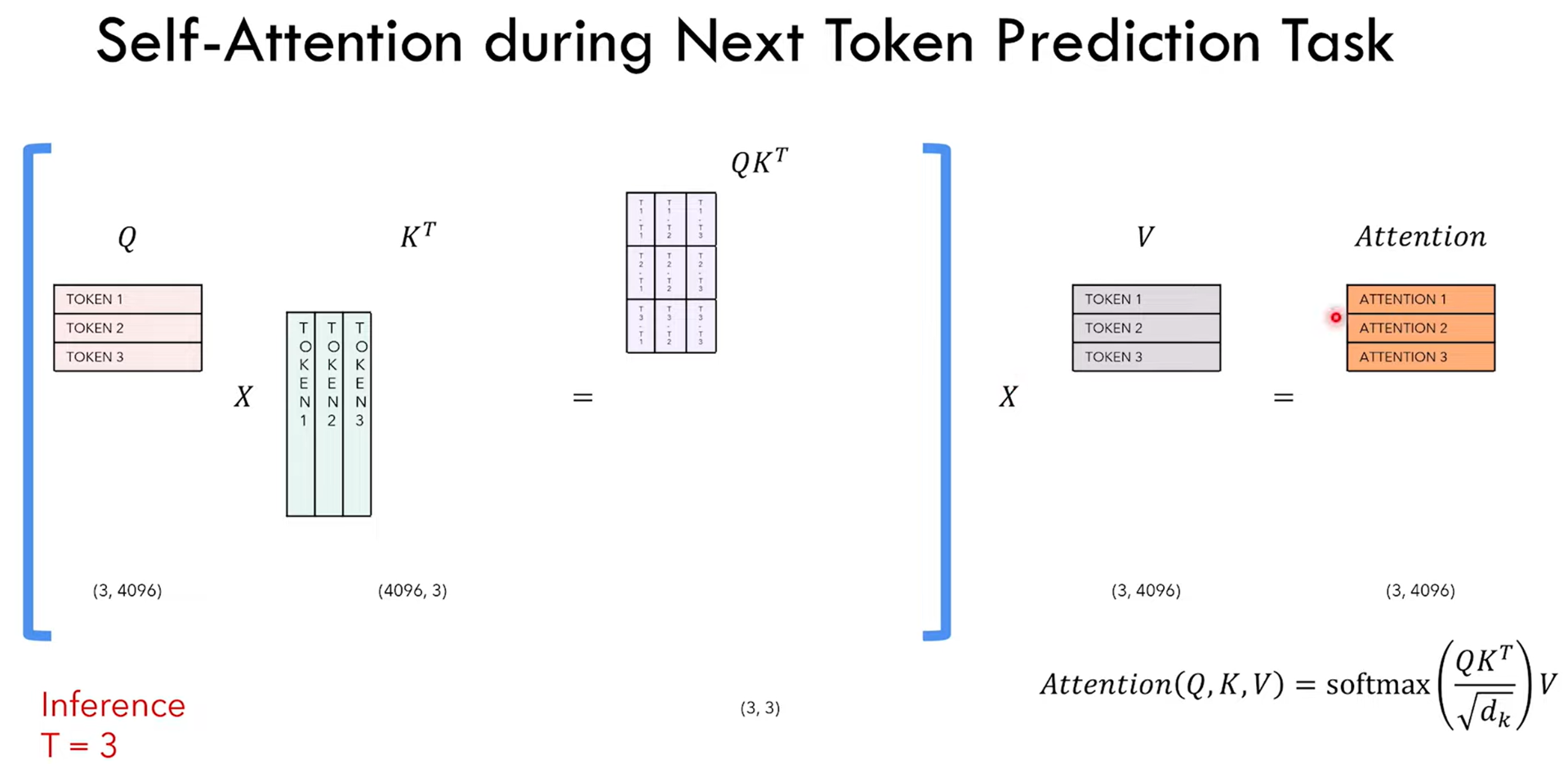
In the task of next token prediction, for each iteration, we only care about the last output token since the previous tokens have already been predicted. But we calculate these tokens in every iteration repeatedly. To avoid that, for each iteration and suppose we have to predict token 3, then we append the token 3 from K to the K buffer, since token 1 and 2 are already there, and append the Token 3 from V to the V buffer, and after the attention layer calculation, we obtain the prediction of token 3.
-
Multi-Query Attention [3] and Grouped Multi-Query Attention [4]
As we have reduced the computation by KV cache, the bottleneck which affects the speed is now becoming the Memory access, according to the ratio of memory and arithmetic operations. So they only divide the Q into multi heads and use a single shared head for the case of K and V. But it will degrads the model slightly, so they use grouped meahcnism like grouped convolution. They are illustrated below.
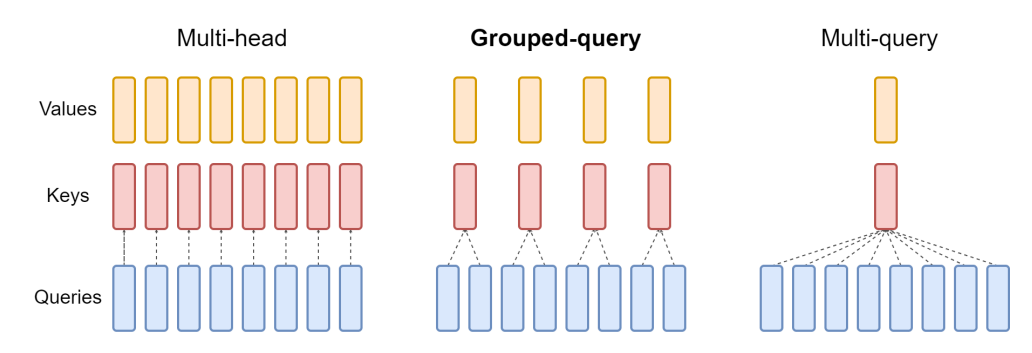
[1] RoFormer: Enhanced Transformer with Rotary Position Embedding
[2] Root Mean Square Normalization
[3] Fast Transformer Decoding: One Write-Head is All You Need
[4] GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints