RAG - Retrieval Augmented Generation
Tutorial: https://www.youtube.com/watch?v=rhZgXNdhWDY
Paper: https://arxiv.org/abs/2005.11401
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Motivation: for sequence to sequence generation models like LLaMa and ChatGPT, they cannot have the latest knowledge since they were trained with old data. To answer question regarding the new knowledge, the use can input some latext documents like wikipeadia as prompt and then ask a question. These documents are usually large, making the model slow.
RAG is kind of method that combines the parametric memory and non-parametric memory to speed up the QA process.
- parametric memory
knowledge stored in the s2s model, which was the original model trained with old data. - non-parametric memory
the retriver to be discussed, that are a separate model trained to have the new knowledge.
Inference
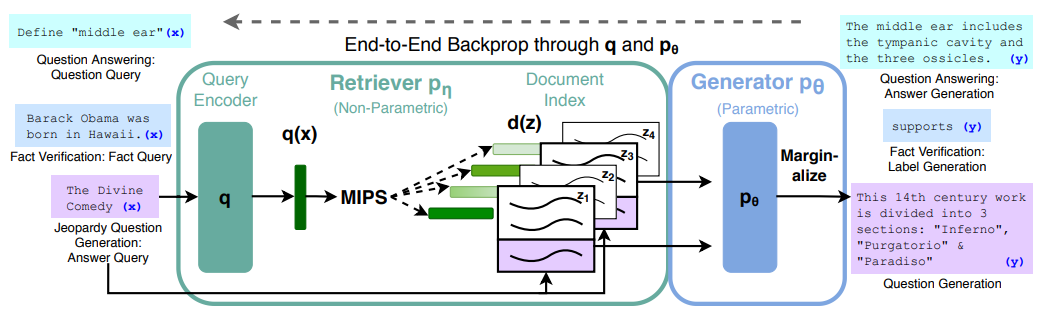
Given the retriever (including a query encoder and a document index/embedder), the process of QA is:
The query x is encoded into q(x) by the query encoder, then find the top-K document embeddings d(z) which have the highest similarities to q(x). The document embedding is the output of the document encoder that encodes the document chunks z (like sentences or document segments). Then we find the associated document chunks z according to d(z) (they have one-by-one map of course), feed both x and z to the original s2s model and obtain the output.
Mathematically, we have:

It reduces the generation time of the original s2s model since we only use K document segments, instead of the whole document, and x as the prompt.
Train
We can train (fine-tune) both the retriever and the original s2s generator end-to-end, given data (x, y) where y is the annotations.
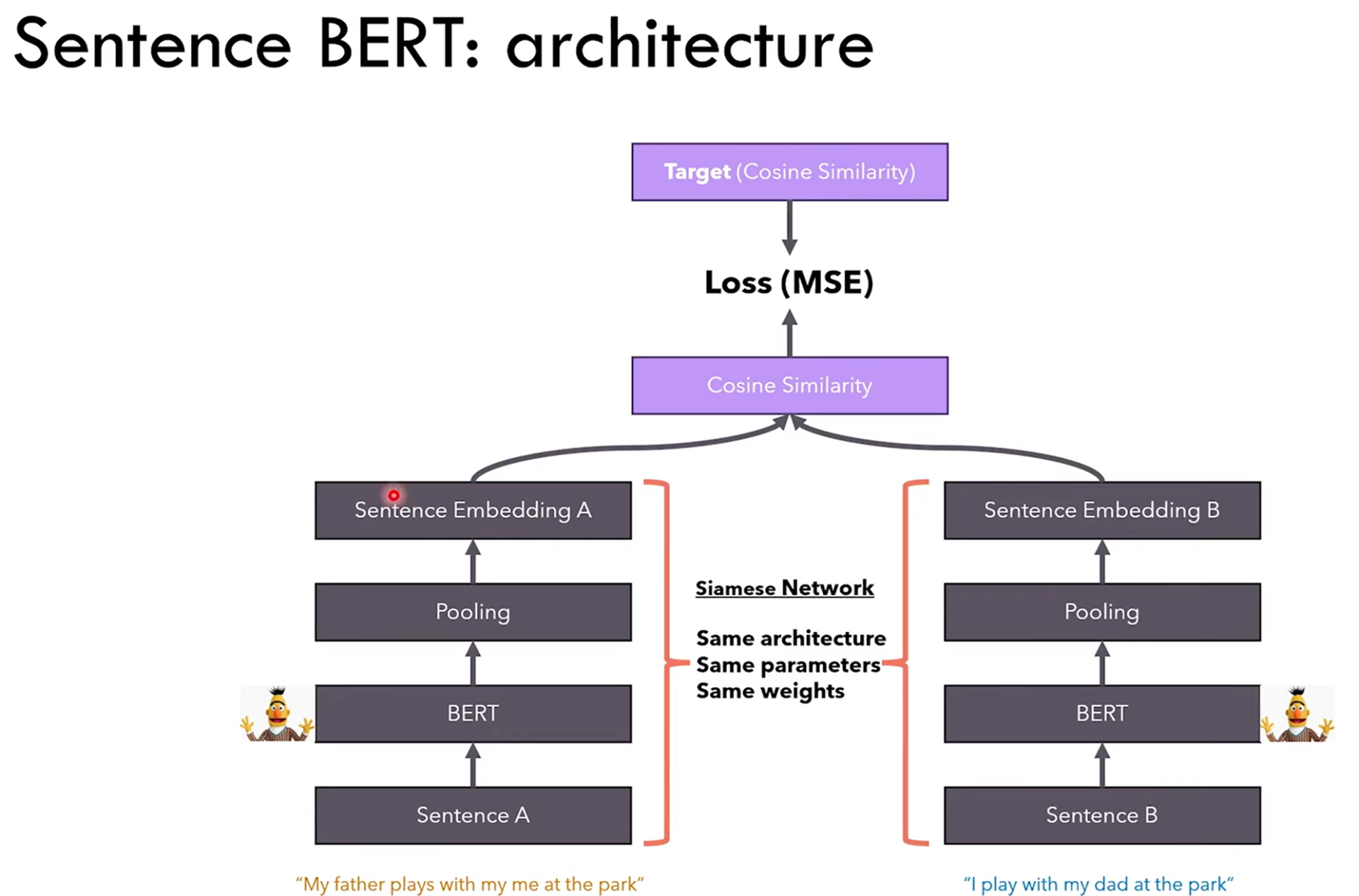
From the tutorial, we can also train the retriever separately, for example using Sentence BERT with a shared BERT architecture for query encoder and document index, to make sure that semantically similar sentence tokens have outputs that have high similarity or short Euclidean distance.