Mistral - Mistral.AI company
Tutorial:https://www.youtube.com/watch?v=UiX8K-xBUpE
Mistral 7B

Paper: https://arxiv.org/abs/2310.06825

For RMS, Rotary Positional Encoding, and Grouped Query Attention, we have introduced in LLaMa.
Mistral is also a decoder based large language models, the goal is to predict next tokens given a prompt.
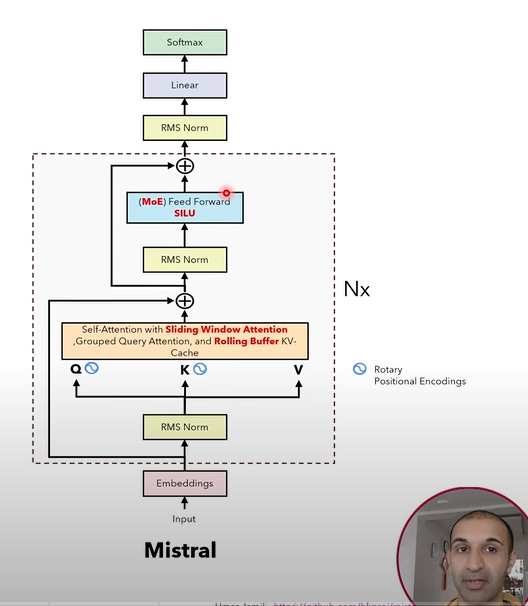
OK, the difference between Mistral and LLaMa is the sliding window attention, rolling buffer KV Cache, sparse MoE feed forward module and the SiLU function used in Mistral.
- Sliding Window Attention
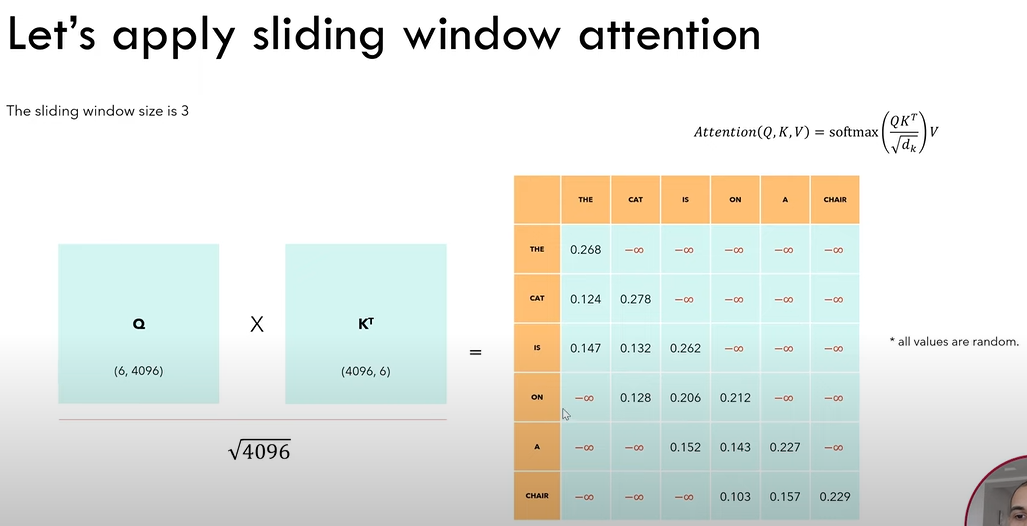
Instead of taking all the previous tokens when predicting the current token, sliding window restrict the the number of previous tokens the current token can see. But indirectly, the receptive field of the current token still include all the previous tokens, similar to the receptive field of features in deep layers of a CNN.
-
Rolling Buffer KV Cache
Due to the existence of sliding windows, the KV cache buffer has fixed size, and the content in the cache is updated in a rolling way.
Pre-fill and chunking are techniques to implement the CV cache, in an memory efficient way. Particularly, the prompt is split into several chunks with each chunking has the size of the sliding window D. For the token to be predicted, the KV cache have values from previous chunk and current chunk, such that the memory only has two chunks of KV but ensure each token can see the previous D tokens. -
MoE Feed Forward
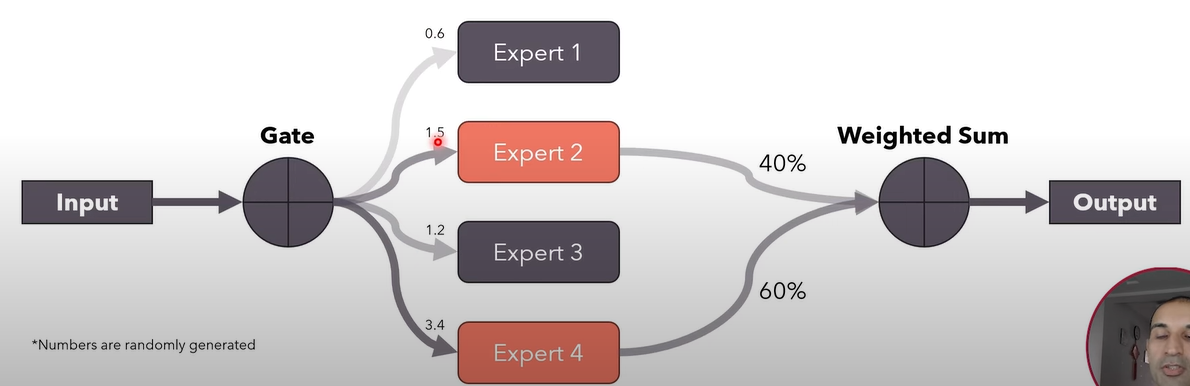
It is like dynamic channel pruning, with a gate to decide which feed forward experts (e.g., the top 2) are used to generate the output. To make sure the scale of the output remain stable, it uses weighted sum to add the selected experts. -
Pipeline Parallelism
Paper “GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism”: https://arxiv.org/abs/1811.06965
If using model sharding, the big Mistral was split to several parts which are assigned to different GPUs in sequence. GPU1 is reponsible for Layer1-Layer4, for example. To finish the whole forward and backward pipleline, we need to wait the previous GPU to excute the next GPU. So it wastes much time.
Using pipeline parallelism, we divide the mini-batch into several micro-batches, and feed micro-batches to GPUs and it can save time. For example, when we feed micro-batch 1 to GPU1, then GPU2 is free now, we can at the same time feed micro-batch 2 to GPU2, smilarly, micro-batch 3 to GPU3, etc. Then when GPU1 finished micro-batch 1, it means other micro-batches are finished by other GPUs, we can then feed micro-batch 1 to GPU2 because GPU2 is now free, and at the same time micro-batch 2 to GPU3, and so on, and we may finally feed micro-batch 4 just finished by GPU4 to GPU1 if GPU1 is free (when it doesn’t take more new batches) to make it work in a cricle.