Mamba
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Tutorial https://www.youtube.com/watch?v=8Q_tqwpTpVU
Paper: https://arxiv.org/abs/2312.00752
The shortage of Transformer is the quatratic computational complexity about the sequence length. Also, during inference, even with KV cache, the computation cost of the later token will be significnatly larger than the early token, as the KV cache is growing. Mamba developes a linear-time sequnce modeling and the computational cost for each token during inference is just the same.
Training: using convolution + Inference: using recurrent network
The whole method is based on state space models, where the formulations are:
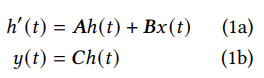
where h(t) is the state representation at time step t (or of the t-th token), x(t) is the input at t, and y(t) is the output at t.
This is a differential equation, but by some discretization process like Euler method, we can convert it into a recurrent process:
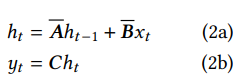
so that it operates like a recurrent network, where $\mathbf{\overline{A}}$ and $\mathbf{\overline{B}}$ are calculated by
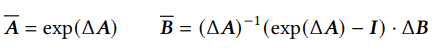
where $\mathbf{\Delta}$ is the time step which are learnable paramters in Mamba.
If we extend h0, h1, h2, …, ht, then
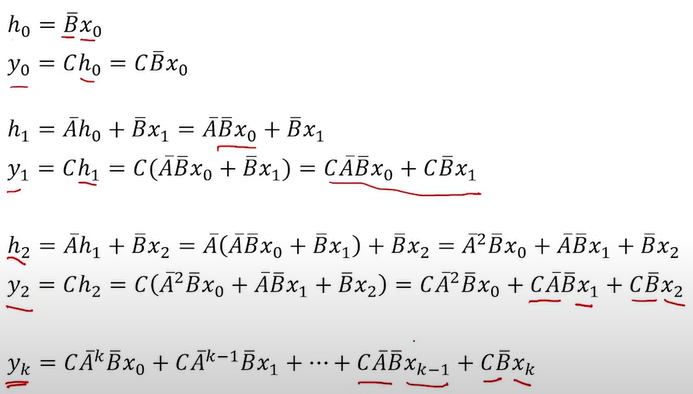
It means we can actually convert it into convolutions with kernel
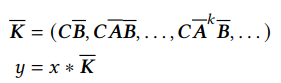
For example,

The good thing is that we could train it with efficient convolution (highly parallelized) and inference it with recurrent operation (with constant computation).
The problem is that if we initialize A and B and regard them as parameters, and using this convolution, then A and B are shared. It also means the kernels are shared for different tokens (or different time steps), so the model cannot deal with the slective coping problem, since the model is not time-varying to selectively remember or ignore inputs depending on their content.
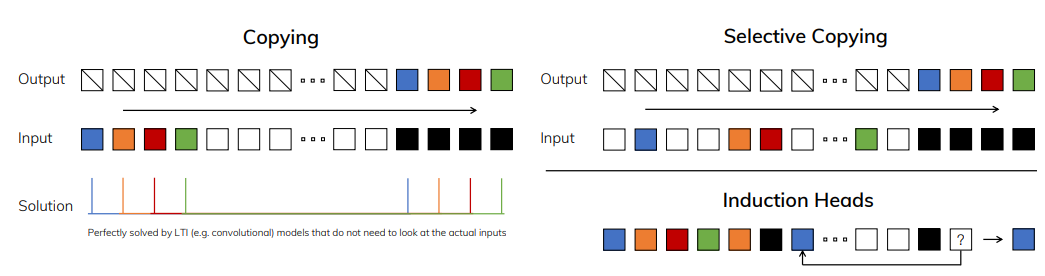
The solution is to use dynamic kernels that depend on the current token on-the-fly. However, it would be difficult to parallelize since the kernels are not shared. Therefore the authors propose the Selective Scan algorithm to increase parallelism and computational efficiency with GPUs.
Performance
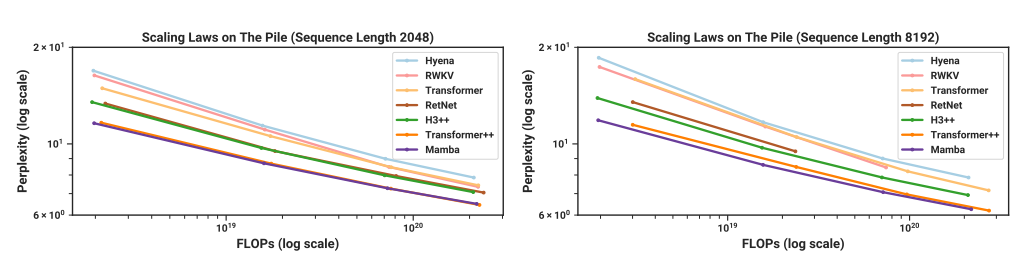
“Transformer++” is the strong transformer based recipe in state-of-the-art methods. Mamba performs nearly the same or superiously.