BLIP-2 - Querying Transformer (Q-Former)
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
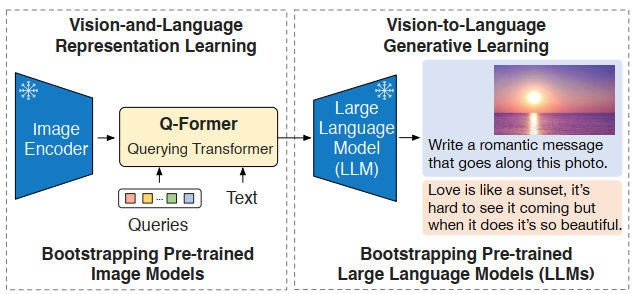
Motivation
Large image models and large language models were trained separately, and it might be difficult for them to directly communicate to do multimodal tasks, like Visual Question Answsering (VQA) and mutimodal retrieval.
Multimodal training is computational costly, and fine-tuning from existing seprated unimodal large models would cause catastrophic forgetting.
So the paper proposes Q-Former to connect them, such that during training, the separate unimodal models are frozen, but only to train the Q-Former to get text-aligned visual features that facilitate multimodal tasks.
Training
Q-Former is trained in two stages. On the first stage, the purpose of training is that given a pretrained image encoder and a text, to make Q-Former output tokens that align with the given text. On the second stage, the output of Q-Former is connected to LLMs as “soft prompt” such that LLMs can generate related text.
1. First stage
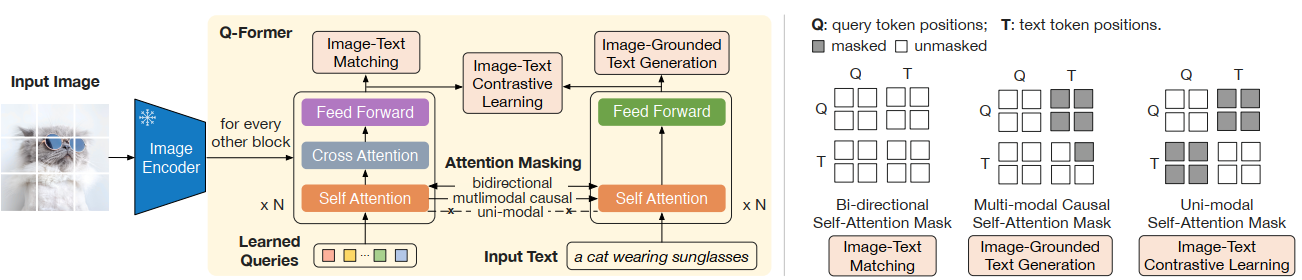
So the big image encoder is frozen, and Q-former consists of two transformer branches as shown above with shared self-attention paramters. The queries of the vision branch are learnable (32 * 768, 32 queries with dimension of 768). In the Cro-attention layer of the vision transformer, keys and values are from the frozen image encoder. The training of Q-Former involves three objectives.
- ITC (Image-Text Contrastive learning)
In the self-attention layer, uni-modal mask is adopted, which means the visual queries can only att end to other visual queries (because it’s self-attention, so queries here are regarded as tokens), not text tokens, and text tokens can also only attend to other text tokens. Like CLIP, a contrastive learning objective is used to align the output of the two transformers. Since the Q-Former costs much less memory than typical multimodal learning methods, so they didn’t use momentum queue in BLIP, but in-batch negatives. - ITG (Image-grounded Text Generation)
So here, in the self-attention layer, the multi-modal causal mask is used, such that visual tokens only attend to other visual tokens, but text tokens attend to all the visual tokens and its previous text tokens. The training objective is a next token prediction decoding task. - ITM (Image Text Matching)
In the self-attention layer, the bi-directional mask is used like in BERT, and compute the similarities between the cls token in the text transformer output and each of the queries in the vision transformer output, getting 32 similarities, and use the biggest similarity score as the matching score. They also use hard negative mining strategy as used in BLIP to create informative negative pairs.
2. Second stage
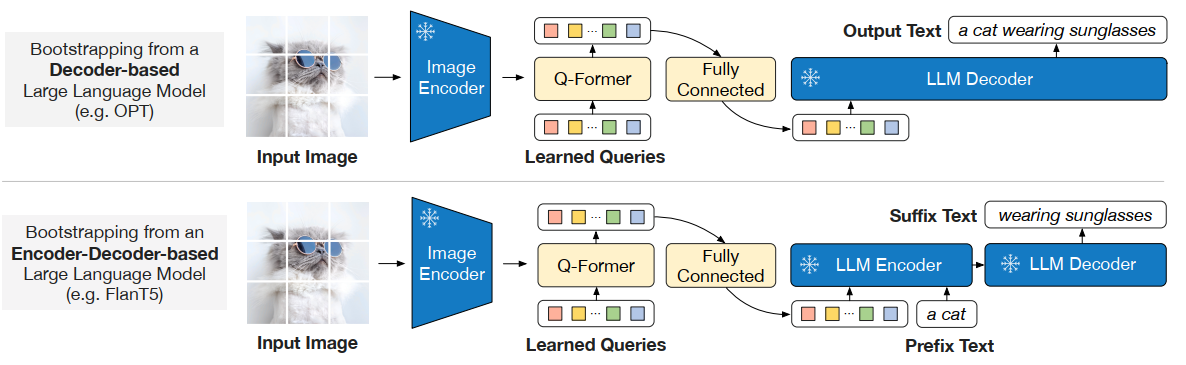
The second stage is quite simple, as we also get the visual prompt from Q-Former (this is done by using FC to transform the dimension of the Q-Former otuput tokens of the vision branch to be compatible with the text tokens for the LLMs). In this stage, decoder-based training or encoder-decoder-based trainin can be used as shown above.
The advantes of BLIP2
- It uses less memory and computation and leverages pre-trained LLMs and large vision models for multimodal learning, without fine-tuning LLMs and large vision models. It acts like an adapter to bridge to make multi modals aligned.
- It can do VQA, it can create dialogue between images and humans through text.