视频理解串讲-1
Video: https://www.youtube.com/watch?v=gK7AGO6okhc
视频理解在深度学习时代有过已下几大探索:

1. 早期CNN - DeepVideo
对于早期CNN方法,代表是DeepVideo, 探索了很多我们早期可能会第一时间想到的各种可能,比如用2D CNN对每帧图像进行处理,结合early fusion, late fusion,slow fusion等等。
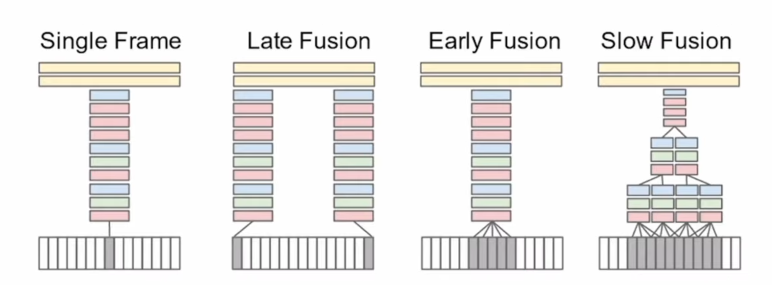
答案就是效果不好。
2. 双流网络
加上时序信息,能显著提升视频理解性能(主要是在动作识别这一任务上进行的探索)
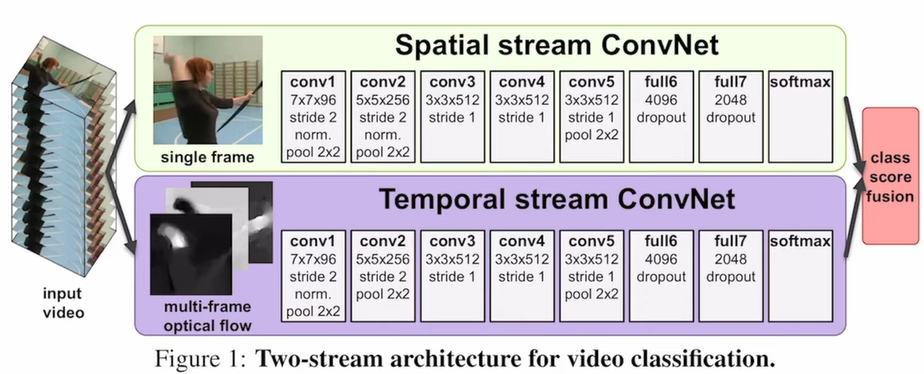
The method is quite simple, first use some basic method to extract the optical flow for video which is then used as temporal information.
The first stream use 2D CNN to process single image frames, the input of which is a single image, and the network is a pretrained CNN on ImageNet.
The second stream use a sequence of optical flow frames (with a fixed number, e.g., 20), and train the network from scratch (because the number of input channels are now becoming 20 instead of 3).
Finally, the output of softmax from the two streams are averaged to give the final score.
The performance is increased from like 60% to 80%, comparable with the performance of the best traditional handcrafted feature based methods. Typical datasets are UCF-101, and Sports-1M.
How to test?
Well, they sample a fixed number of frames from each test video, no matter how long the video is. Then they use corner crops and center crop for each video frame, plus flipping, getting 10 times bigger than the original sampled test data. For each 1 of the 10 versions of video, they use this two-stream network to get a score, and do averaging to get the final score.
Tips
- They use mean subtraction to alleviate the camera motion.
- They use bidirectional optical flows (forward and backward, respectively).
Other possible tricks (also appear in different papers)
- Combine space fusion and temporal fusion. Space fusion is implemented by simpling summation, concatenation, or stack-and-conv operations to fuse features from the two streams. For temporal fusion, we could use 3D conv, or pooling to fuse features from consecutive frames.
- Initialization of temporal network from pretrained 2D network on ImageNet. Since the number of input channels of the network is changed from 3 to 20, an effective way to initialize the network for the first layer is to firstly averaging the 3 channels’ corresponding parameters and repeat it 20 times.
- Partial BN, which only learn the BN parameters for the first BN, and keep the rest of the BNs frozen.
How to effectively deal with long videos?
Future work 1: Beyond short snippets
It is a paper to solve the problem:
The initial idea would be using pooling to aggregate the information from multiple frames. So they have investigated like max pooling, average pooling, and Convolutional pooling.
Finally, they use LSTM to do the pooling. But the effect was not that good, it might because that the test videos like in UCF-101 are too short, repeatedly feedinding features of video frames that might be very similar with each other, can not fully utilize the advantage of LSTM.
Future work 2: Temporal Segment Networks (TSN):Towards Good Practices for Deep Action Recognition.
This paper is quite straightforward but absolutely effective. 简单有效!ECCV 16.
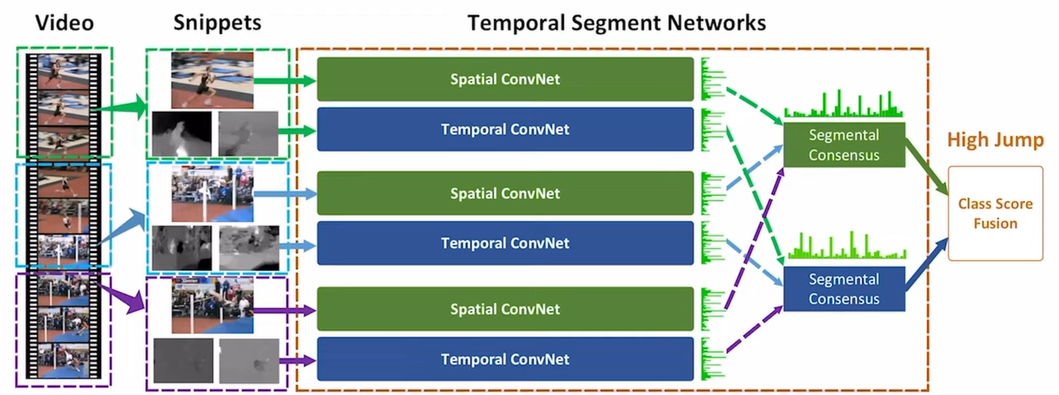
So they segment the long video into pieces. For each segment, they sample a frame, and a sequence of optical flow frames based on that frame, generating the space logits and temporal logits through a two-stream network. Then they aggregate all the space logits together, so called segmental consensus, by pooling, summation, or even LSTM to get the space-related score. Similarly, they aggregate the temporal logits to get a temporal-related score. Then they fuse the scores to get the final prediction.
My comments (may not from the paper): For long video, it is possible to sparsely segment the video, or increase the length of each segment.
The above is supervised learning. It can also do unsupervised contrastive learning, the work done by team of 朱毅 (the tutorial speaker)
Generally, they have three segments, and they extract a image frame and a sequence of optical flows from each segment, obtaining 3 image frames and the corresponding 3 optical flow sequences, being one sample of a pair. Then they repeat the process to obtain another 3 images and 3 optical flow sequences, being the other sample of the pair. So this pair can be regarded as a positive pair, because they are extracted from the same segment group. Similarly, they can extract a negative pair by using two different segment groups.