视频理解串讲-2
Video: https://www.youtube.com/watch?v=J2YC0-k57NM
C3D
3D convolution, easy to understand. Circumvent the use of optical flow, which is time-consuming. But 3D conv itself is also time-consuming with heavy computations.
I3D
Inflated 3D Conv, the advantage is that it can be initialized from pretrained 2D CNNs, where the 2D kernels are inflated into 3D kernels, by copying the parameters T times and dividing it by T (T is the termporal dimension of the kernel).
Non-local
It is similar to self-attention, can be formed in spatial space or temporalsptial space.
R(2+1)D
Factorize 3D conv into 2D in space and 1D in time.
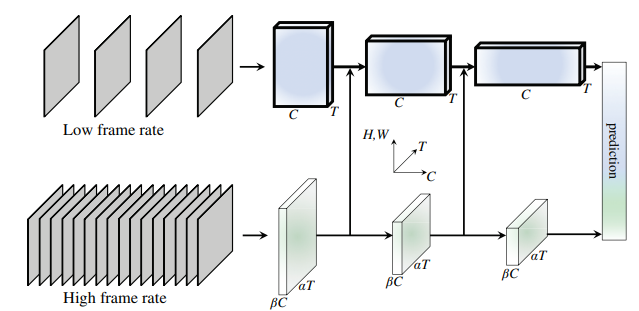
SlowFast
TimesFormer
Decompose the 3D attentions into 2D attentions in space dimensions and 1D attentions in time dimension.
Thoughts about how to do long video understanding
- Transformer, Non-local to capture long-term dependencies.
- RNN like structures, like LSTM, Mamba, and TTT.
- Local-global attentions (MobileViT, Swin Transformer, etc.) to save computation.
- Use factorized/decomposed operators (like R(2+1)D, TimesFormer, etc.) to save computation.
- For the case the number of tokens is huge, then using techniques like sampling, or sliding window to do self-attention.
Local-global attention is that we do self-attention in local tokens, and then select local representative tokens for global self-attention.