Megatron-LM (1)
Resources about distributed training with Megatron-LM
Github: https://github.com/NVIDIA/Megatron-LM
Document on NeMo: https://docs.nvidia.com/nemo-framework/user-guide/latest/overview.html
NeMo is a cloud-native generative AI framework built on top of Megatron-LM.
Overall view of Megatron-Core: https://docs.nvidia.com/megatron-core/developer-guide/latest/index.html
Official APIs with formal product support…
Megatron-LM are basically based on the following three papers. Let’s do some notes on them.
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
paper (2020, arxiv): https://arxiv.org/abs/1909.08053
Contributions
- Put large transformer models into different GPUs (with
tensor model parallelism) to solve the problem that a single GPU cannot fit the whole model. - No need to design custom C++ code, compatible with existing Pytorch transformer implementations.
- Able to train a GPT-2 with 8.3 billion parameters and a BERT with 3.9 billion parameters.
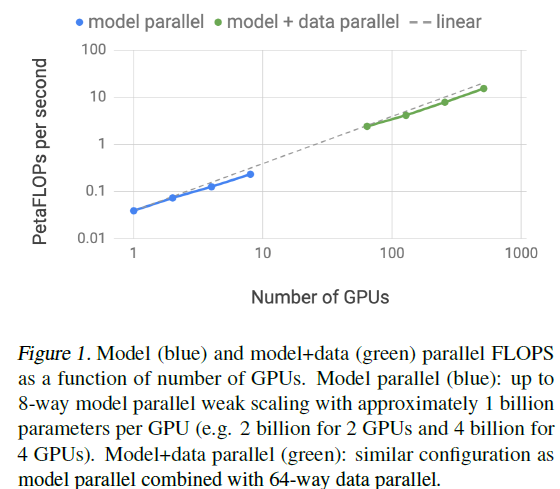
On the above figure, model parallel means using tensor model parallelism methods proposed in this paper. Evaluation is based on weak scaling.
Methods
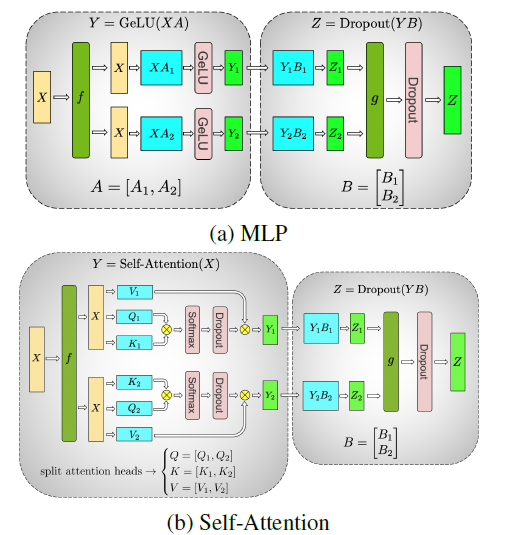
The tensor model parallelism can be described by the above illustrations. Generally it is designed for equally partitioning transformer blocks (MLP and self-attention layers) into different parts which are stored in corresponding GPUs. Above figure uses 2 GPUs, it means both MLP and Self-Attention layer are segmented equally with two parts, with each part put in a GPU during training.
For MLP, we have the following equations:
$$ Y= \text{GeLU}(XA) $$
$$ Z = \text{Dropout}(YB) $$
where X and Y are activations, A and B are parameter matrices. A is split along columns such that the GeLU nonlinear function can be put in individual GPUs separately, leading to $Y_1$ and $Y_2$. Then B is split along rows giving $Z_1=Y_1B_1$ and $Z_2=Y_2B_2$. Before dropout, we should have $Z=Z_1 + Z_2$, therefore, we use “all-reduce” operator to calculate the sum from different GPUs and distribute the result back to all GPUs, then dropout operator is executed in each GPU that outputs $Z$ (here I guess each GPU should share the same dropout mask).
In this way, the “f” function is actually a non-operation (or Identity function) and “g” is an all-reduce function in the forward pass. In the backward pass, “g” becomes Identity function and “f” becomes an all-reduce function. These two functions are the so-called conjugate functions.
For Self-Attention layer, we make use of the multi-head attention mechanism to do tensor model parallelism. X, again, is shared in all GPUs, while each GPU have its separate sets of attention heads where the K, Q, V are generated with its own linear projection matrices. Similarly, B is split in rows and all-reduce is applied before dropout.
Overall, after applying such tensor model parallelism, for each transformer layer (consisting of a attention layer and a MLP layer), there are 4 total communication operations in the forward and backward pass of a single model parallel transformer layer, i.e., four all-reduce operations involved in forward and backward passes.
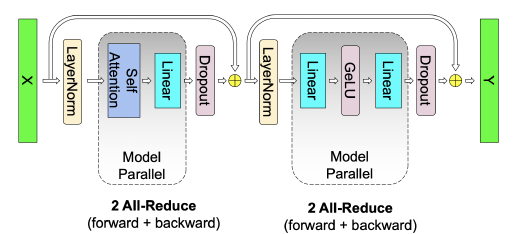
Other notes
-
For output embedding $E_{H\times v}$ which transforms the hidden size H to vocabulary size v, we split $E$ along columns to $E_1, E_2$ and multiply with the output of the last transformer layer to get $[Y_1, Y_2] = [XE_1, XE_2]$, then instead of using all-gather to gather $Y_1, Y_2$ to $Y=[Y_1, Y_2]$ and distribute it to each GPU followed by cross-entropy loss (this may cause the all-gather operation to communicate $b\times s\times v$ elements in $Y$ where b is batch size and s is sequence length), they fuse the output of $[Y_1, Y_2]$ with the cross entropy loss to reduce the dimension to $b\times s$. (Though here I don’t know how they fuse that :<).
-
For communications between GPUs, they use NVSwitch with 300GB/sec bandwidth for intra-server and 8 InfiniBand adapters per server with 100GB/sec bandwidth for inter-server communications.
Scaling evaluation on GPT-2
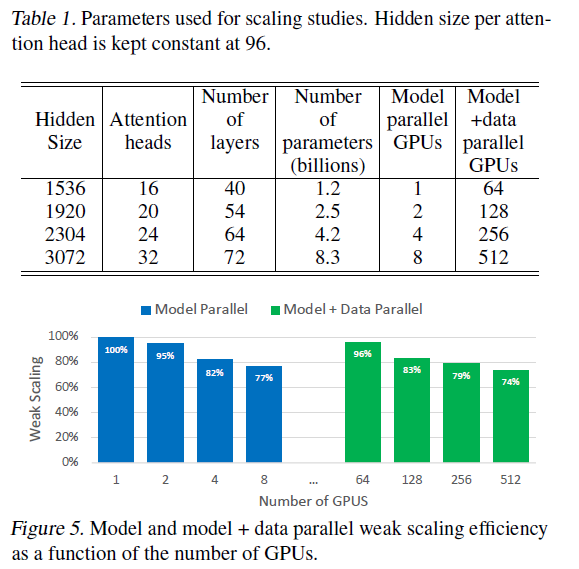
Here, 100% is for the baseline regarding the training throughput. Other percentages are relative to the baseline.