ZeRO-Offload
ZeRO-Offload: Democratizing Billion-Scale Model Training
paper (2021 arxiv): https://arxiv.org/abs/2101.06840
My memory on ZeRO-Offload
ZeRO-Offlad helps multiple GPUs to scale to larger models that have more number of parameters by offloading the part of the memory to CPUs during training, without affecting the efficiency.
Way of thinking:
- As much memory as possible offloaded to CPUs.
- The communication overhead should be as small as possible.
- The computation overhead on CPUs shouldn’t affect the training efficiency.
Here is the solution for offloading:
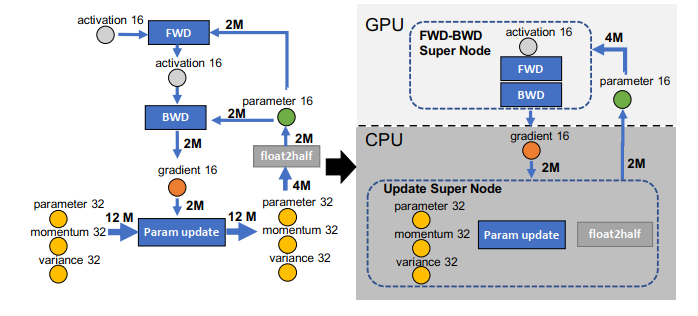
Based on that, the authors propose to offload the optimizer (i.e., Adam optimizer) to CPUs where mixed precision training is applied, where 16-bit parameters are located in GPUs, but 16-bit gradients, 32-bit parameters, 32-bit variance, and 32-bit momentum[^1] are located in CPUs. Particularly,
- For the single-GPU case, after the 16-bit gradients are obtained by backward propagation in GPU, they are offloaded to CPUs and the optimizer uses the gradients for calculating parameter updates. Then the updated 32-bit parameters are converted to 16-bit which are then moved back to GPU.
- For the multi-GPU case, where ZeRO-2 is applied, then during the backward propagation, gradients are calculated from back to front. When a certain part of parameters got the gradients, the gradients are averaged by the reduce operator and sent to the corresponding data parallel GPU, which are then offloaded to CPU. After the step function is executed in CPU, the updated parameters are convreted to 16-bit and sent back to the GPU, followed by the all-gather operation or broadcast operation[^2] when parameters are updated and located in GPUs (the actual communication process may differ according to the communication strategy when applying ZeRO-2 and the offload method).
- The step function in CPU for the gradients of parameters in later layers and the GPU->CPU communication can actually be overlapped with backward computation for parameters in previous layers,
- For small batch sizes, the communication and computation in CPUs would occupy a big part of the overall computation, which may be a bottleneck of the throughput. Therefore, the authors proposed to delay the CPU offloading by one iteration, to make sure that the CPU computation can be overlapped with the GPU computation.
Some interesting results
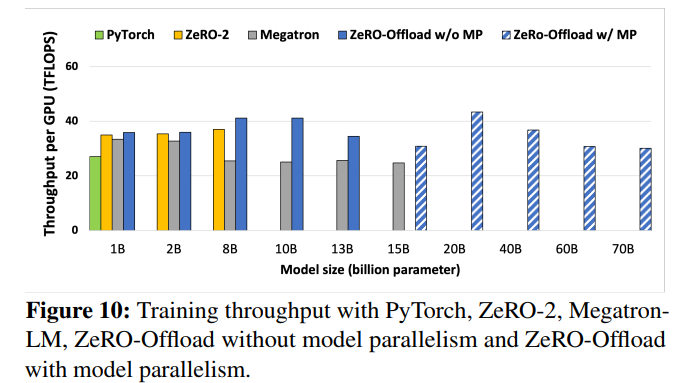
For Figure 10 where a single DGX-2 node is used (16 GPUs), each experiment uses a fixed total batch of 512 (possibly use gradient accumulation). For 1B-15B models, ZeRO-Offload achiever higher throughput than any model because it allows to train with larger batch sizes since the GPU memory is partially offloaded to CPUs. ZeRO-Offload with model parallelism can scale to a 70B-parameter model.
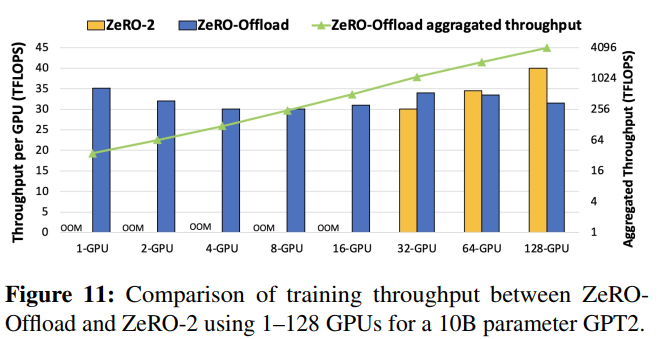
For Figure 11, with more GPUs (such as 64 and 128), ZeRO-2 starts to outperform ZeRO-Offload, because both can now run similar batch sizes, achieving similar computation efficiency, whereas ZeRO-2 does not suffer from the additional overhead of CPU-GPU communication.
[^1] In mixed-precision training, Adam optimizer state has 32-bit parameters, variance, and momentum, while the model itself has the 16-bit parameters and gradients.
[^2] For all-gather operation, the the CPUs will execute the step function in parallel when the whole backward propagation is finished and all the gradients are offloaded to CPUs. Then the updated parameters in optimizer states will be moved back to the corresponding GPUs followed by this all-gather operation. For broadcast operation, the CPUs execute step function sequentially once a certain part of gradients are calculated and offloaded to the CPUs. Similarly, the updated parameters will be moved back to the corresponding GPU. Since these parameters only in a single GPU now (in ZeRO-2 data parallelism), they are broadcast to other GPUs.