Megatron-Turing NLG 530B
Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model
paper (2021 arxiv): https://arxiv.org/abs/2201.11990
Model architecture and training hyperparameters
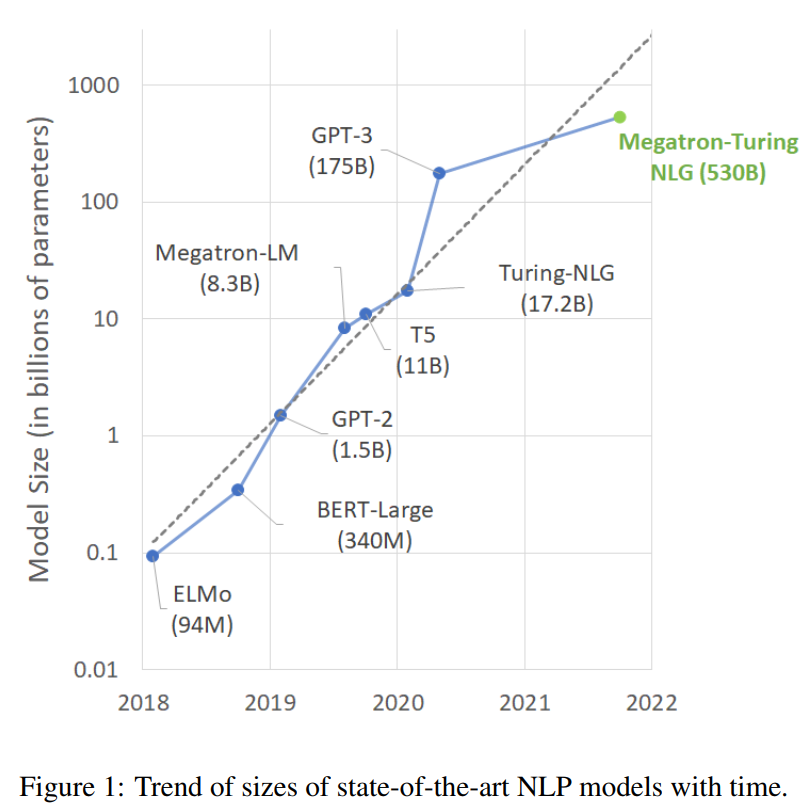
The model has 510B parameters scaled from the transformer decoder. Sequence length is 2048, and the global batch size is 1920.
- LR: use 1B tokens to linearly warmup LR to $5.0e^{-5}$. The LR is then decayed to 10% of its value over 340B tokens with cosine decay.
- Batch size: starts at 32 and gradually increases to 1920 with a step of 32, in the first 12B tokens.
- Weight initialization: normal distribution with 0 mean and standard deviation of $4.0e^{-3}$
- Optimizer: Adam, $\beta_1=0.9$, $\beta_2=0.95$, $\epsilon=10^{-8}$.
- Gradient norm clipping at 1.0, weight decay 0.1.
Dataset
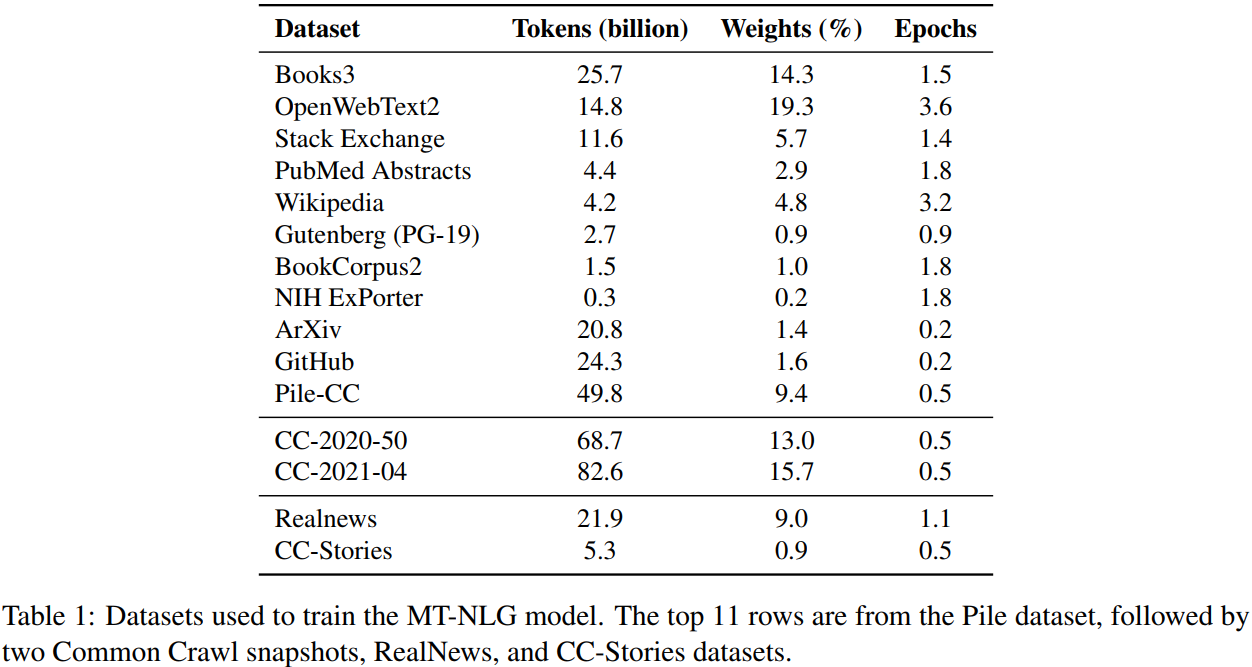
In total 339B tokens.
Parallelism in training
Overall: ZeRO Data parallelism + Megatron-LM Tensor parallelism + 1F1B Pipeline parallelism.
Considerations on bandwidth
- Tensor parallelism has the largest communication overhead of the three strategies, and so we prioritize placing tensor parallel works within a node.
- Pipeline parallelism has the lowest communication volume, and so we can schedule pipeline stages across nodes.
- Data parallel works are placed within a node to accelerate gradient communications when possible, otherwise are mapped to nearby nodes when possible.
Parallelism degree
- Each 530B parameter model replica spans 280 NVIDIA A100 GPUs, with 8-way tensor parallelism within a node and 35-way pipeline parallelism across nodes. Data parallelism is used to further scale out to thousands of GPUs.
- Model is trained with mixed precision on NVIDIA’s Selene supercomputer with 560 DGX A100 nodes, with each node having 8 NVIDIA 80-GB A100 GPUs (so in total 4480 GPUs). GPUs are connected with NVLink and NVSwitch within node and Infiniband across nodes.
Results
On LAMBADA