Other papers on DeepSpeed-MoE
A Hybrid Tensor-Expert-Data Parallelism Approach to Optimize Mixture-of-Experts Training
This paper further adopts tensor model parallelism from Megatron-LM with Expert parallelism and ZeRO data parallelism for MoE model training. The design spirit is similar to DeepSpeed-MoE:
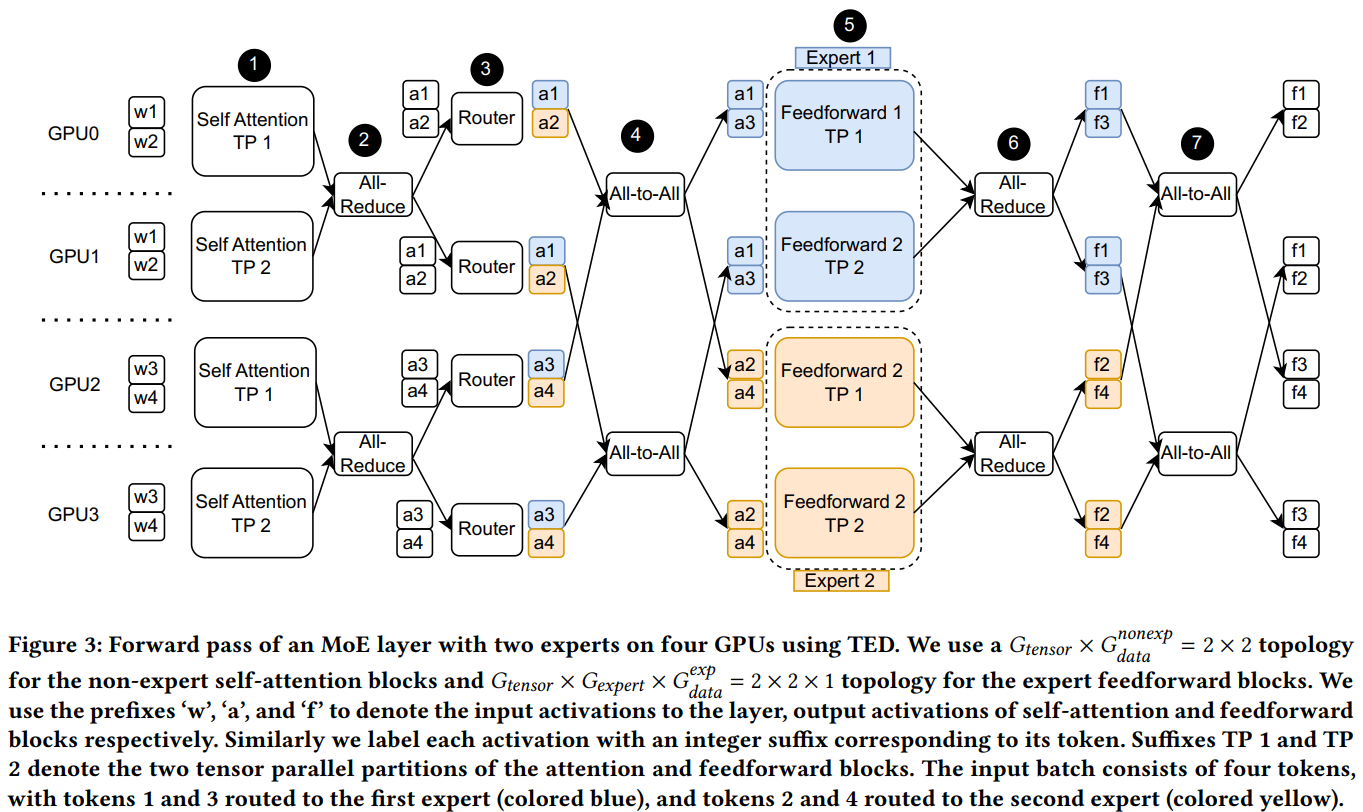
In forward pass, two “all-reduce” and two “all-to-all” for each transformer layer. In backward pass, an additional “all-reduce” operator is used to synchronize gradients from different data parallel groups.
The authors in this paper also proposed a tiled version of optimizer that partitions the parameters into tiles which could be process sequentially, so that the temporary memory for 32-bit gradients is independent of the number of experts and the base model sizes.
Scaling Vision-Language Models with Sparse Mixture of Experts
This is an application on VLM.
Architecture
Similar to BeiT v3, but replace the FFN every second layer with the expert layer (only for the first $L-F$ layers, normal FFN in the last $F$ layers).
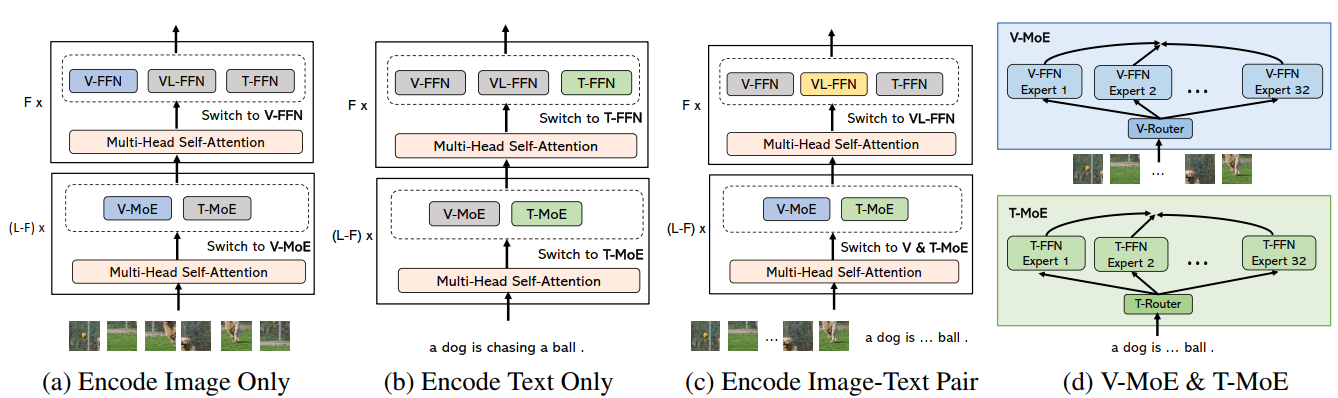
The first $L-F$ layers are for unimodal inputs, where text or image tokens are fed accordingly to V-MoE or T-MoE. The last $F$ layers have additional VL-FFN that can take data if the input is image-text multimodal input.
Training objectives
It uses masked data modeling like BeiT v3.
- For texts, like BERT, the mask ratio is 15% and the model is trained to recover the masked tokens.
- For images, like MAE, using block-wise masking but mask ratio is 40%, the input image is tokenized using the tokenizer in BEiT v2, where tokens are discretized (similar to VQ-VAE).
- For image-text pairs, text and image mask ratio keeps the same as MLM and MIM (i.e., 15% and 40% I think), and the masked contents need to be recovered by the model based on multimodal input.
Training objectives will also consider the loading loss for experts.
During fine-tuning, all the MoE modules, i.e., routers and experts, are frozed.
Model configuration and size
| Model | #layers | L-F/F | #parameters | Maximum sequence length/Tokenizer | Image resolution/Tokenizer | Batch size | Content in each batch | Training steps/epochs |
|---|---|---|---|---|---|---|---|---|
| Base | 12 | 9/3 | 2B (180M per token) | 128/SentencePiece | 224x224/BEiT v2 tokenizer | 6144 | 2048 images, 2048 texts, 2048 image-text pairs | 200k steps/40 epochs |
| Small | 8 | 7/1 |
Dataset for pre-training
| Modal | Dataset | Size |
|---|---|---|
| Text | English Wikipedia, BookCorpus | 4.7B words for EW + 1B words for BC |
| Image | ImageNet-22K | 14M images |
| Text-Image | Conceptual Captions, SBU Captions, COCO, and Visual Genome | 4M images and 10M image-text pairs in total |
Performance on fine-tuning on downstream tasks
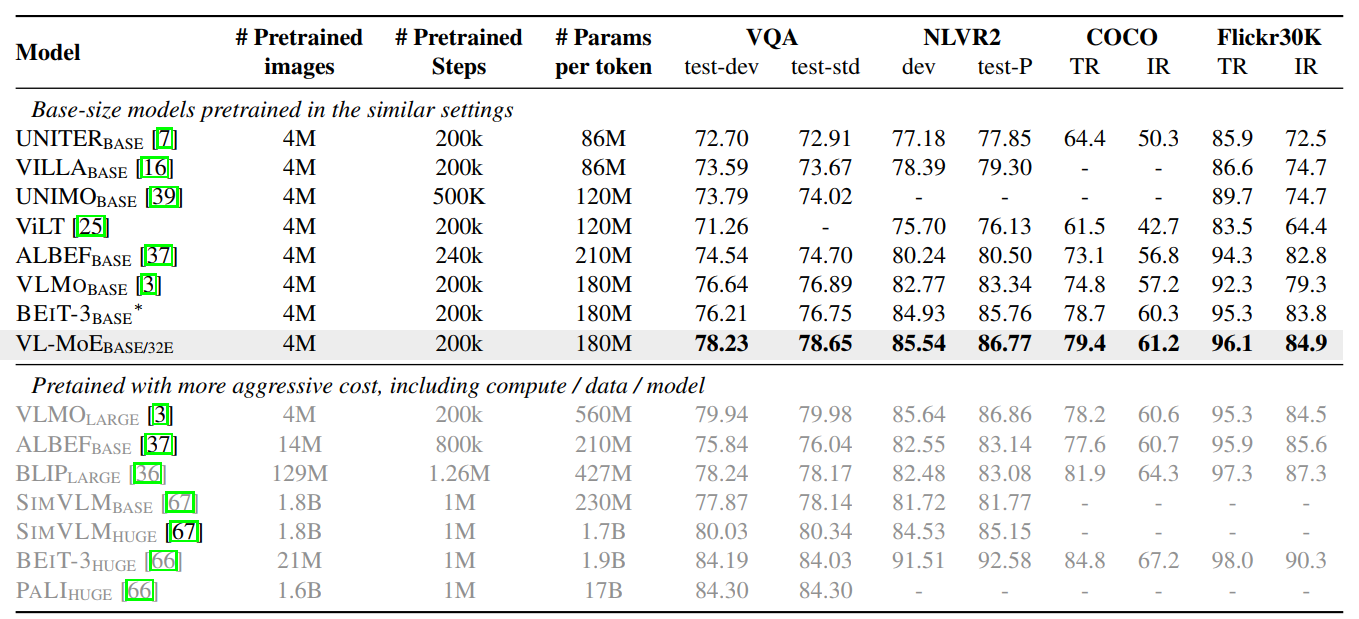
Above is for VL tasks.
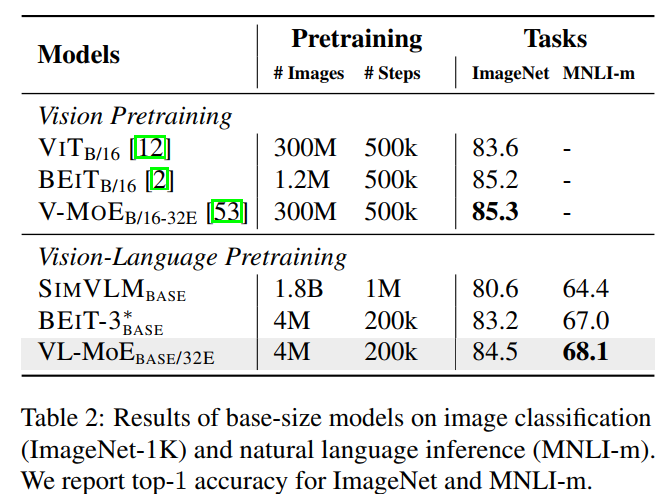
Above is for Vision/Language only downstream tasks. ImageNet has 1.3M images with 1K classes, and MNLI has 433K sentence pairs.