DeepSeek Series - VLM
Paper list
- DeepSeek-VL: Towards Real-World Vision-Language Understanding
- Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation
- JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation
- DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
- Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
General information
DeepSeek-VL and VL2 are two multimodal models for understanding, no visual generation.
Janus series are text and image generative models. Among them, Janus and Janus-Pro use autoregressive mechanism for the image generation, while JanusFlow use Rectified flow, like the diffusion models, to iteratively refine the generated contents from a noise to an image.
DeepSeek-VL: Towards Real-World Vision-Language Understanding
| Number of tokens for pretraining | Model size options | Training pipeline | Performance |
|---|---|---|---|
| A diverse range of data source | 1.3B, 7B | Adapter+ Joint training + Instruction tuning | Comparative to state-of-the-art |
Overview
- Open-source, it’s the most important one for the first DeepSeek paper (here, of the VLM series).
- Deal with both high and low image resolutions using two encoders;
- Preserve language capability via a modality warm-up strategy.
Method
Data
In a few words, they encompass a diverse range of publicly accessible sources, in addition to a selection of proprietary data. They also collect a bunch of supervised fine-tuning data from a diverse range of multimodality and language data sources.
Architecutre
So the architecture consists of three parts:
- The hybrid vision encoder.
- SAM-B, a pretrained ViTDet encoder that accepts $1024\times 1024$ image inputs.
- SigLIP-L encoder for $384\times 384$ image inputs.
With these two encoders, the image’s semantic and detailed information are both preserved.
- Vision-Language adaptor
The input to the adaptor is the concatenated output from the two vision encoders. The adaptor transforms the input into the LLM’s input space through some MLPs. - Language model
Use DeepSeek LLM, so the model is initialized from a selected checkpoint of DeepSeek LLM’s pretrained model.
Training pipeline
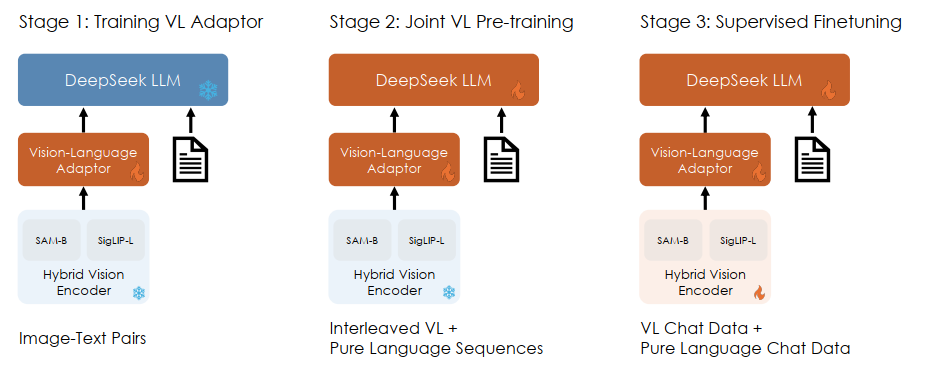
The training objective is the next token prediction.
Like above, on stage 1 they train the adaptor to establish a conceptual link between visual and linguistic elements within the embedding space. On stage 2 jointly train the adaptor and LLM and use a ratio of roughly 7:3 of language to multimodal data, to enable the model to maintain its language capabilities while achieves better pretraining on multimodal data. On stage 3 they conduct supervised fine-tuning and train all parameters.
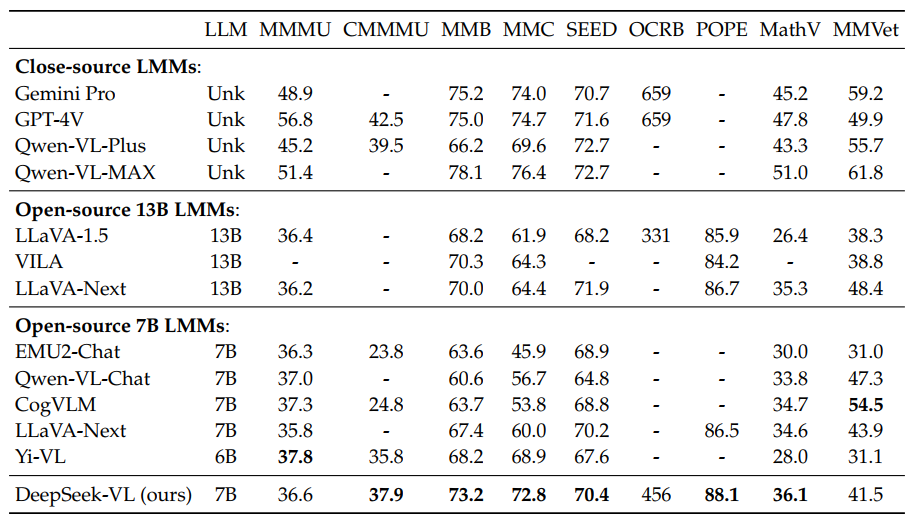
DeepSeek-VL-7B consumed 5 days on a cluster of 64 nodes, each comprising 8 Nvidia A100 GPUs, while DeepSeek-VL-1B consumed 7 days on a setup involving 16 nodes. Here is the performance:
DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
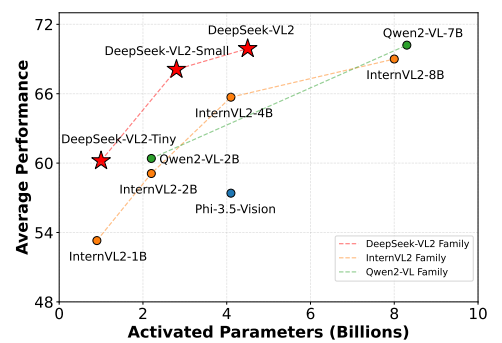
| Number of tokens for pretraining | Model size options | Training pipeline | Performance |
|---|---|---|---|
| An improved data | 3B / 0.57B activated 16B / 2.4B activated 27B / 4.1B activated |
Alignment+ Joint training + Instruction tuning | Shown above |
Overview
- Using dynamic tiling to tackle any resolutions;
- Okay, now we have the DeepSeekMoE architecture.
- Maybe better data for training and some change on the training pipeline.
Method
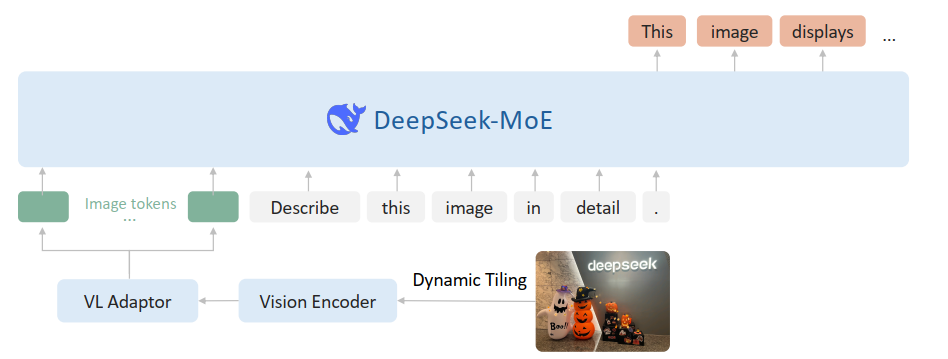
The above figure shows the overall framework. So, first the dynamic tilling approach. It’s quite simple, as shown below.

We basically use a single SigLIP-SO400M-384 vision encoder and divide the original image into many $384\times 384$ tiles and do the encoding.
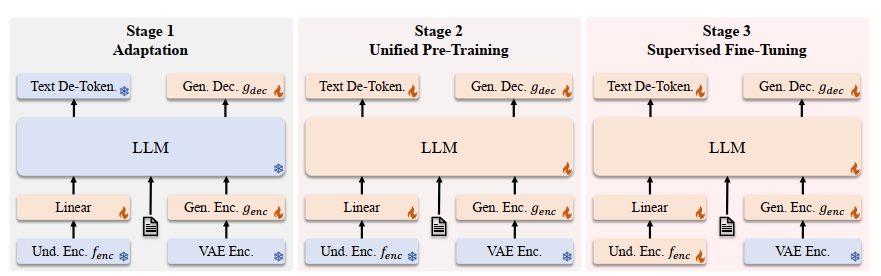
Then the architecture adopts the MoE version, and the pretraining data contains both multimodal data and pure language data to preserve the language capabilities. The rest of the others are quite similar to VL. Note that for the training pipeline, the stage 1 will optimize both the adaptor and the vision encoder.
That’s all to mention here.
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation

| Number of tokens for pretraining | Model size options | Training pipeline | Performance |
|---|---|---|---|
| - | DeepSeek LLM (1.3B) | 3-stage training | Shown above |
Overview
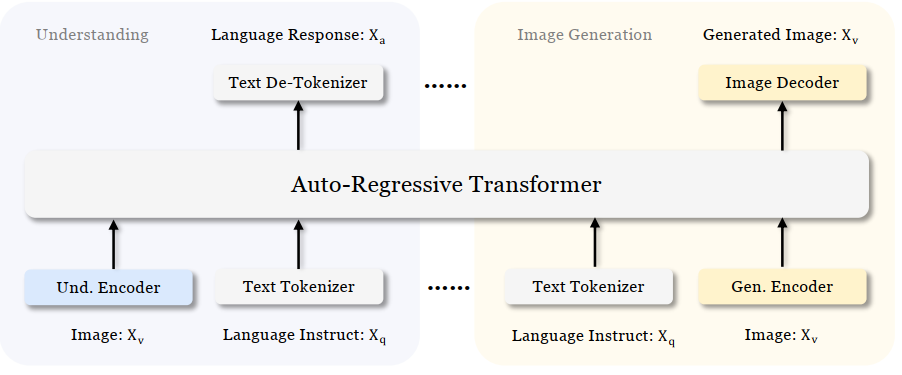
The main ideas:
- Entire model adheres to an autoregressive framework;
- Janus decouples visual encoding for visual understanding and visual generation. I.e., it uses two vision encoders and two adaptors.
Method
Vision encoders and adaptors
| Encoder and adaptor | |
|---|---|
| Understanding | SigLIP, the feature maps are flattened to 1-D + an adaptor to map the feature to LLM input space |
| Generation | A VQ tokenizer, similar mapping to LLM input space |
The output of the two adaptor are concatenated and fed to the LLM.
Training pipeline
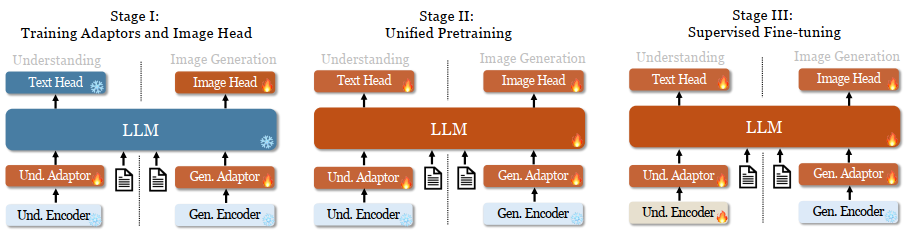
For stage 1, the dataset includes 1.25M image-text paired captions from ShareGPT4V, and 1.2M images from ImageNet-1K where the text is organized as ‘<category_name><image>’.
For stage 2, they use 1) text-only data, 2) interleaved image-text data, and 3) image caption data, 4) table and chart data, and 5) visual generation data.
For stage 3, they use instruct tuning data.
Flame symbols/snowflake symbols in the diagram indicate the module updates/does not update its parameters.
Maybe that’s all for the paper.
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
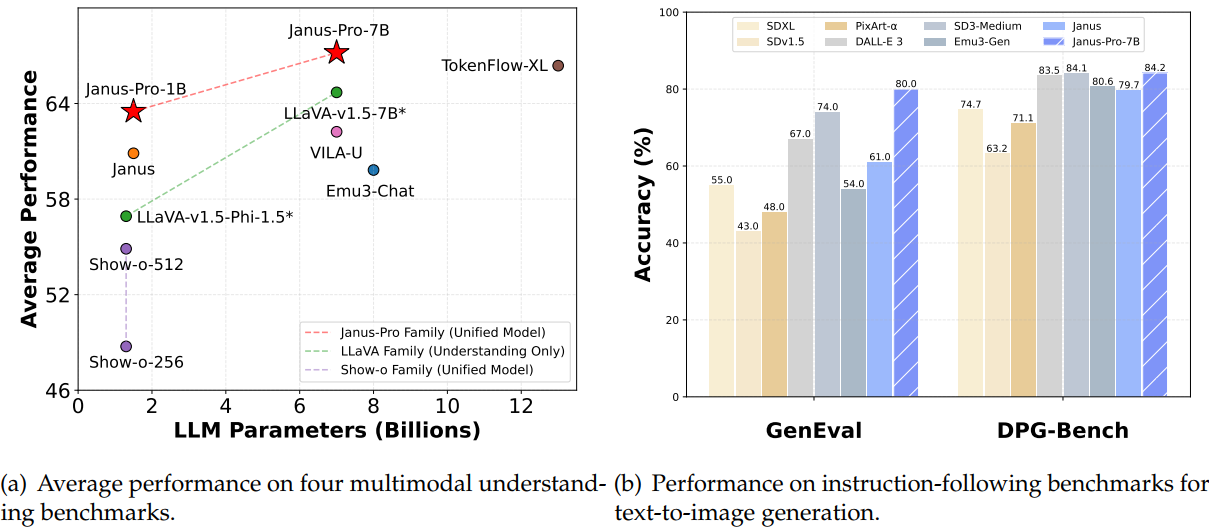
| Number of tokens for pretraining | Model size options | Training pipeline | Performance |
|---|---|---|---|
| - | 1B, 7B | 3-stage training | Shown above |
Overall
Compared with Janus, the Pro version incorporates:
- an optimized training strategy,
- expanded training data,
- scaling to larger model size.
Method
So for the training pipeline, I’ll directly take a snip from the paper to tell the main modification:

Besides, they also scale the data and model size for better performance.
Maybe that’s all.
JanusFlow: Harmonizing Autoregression and Rectified Flow for Unified Multimodal Understanding and Generation

| Number of tokens for pretraining | Model size options | Training pipeline | Performance |
|---|---|---|---|
| - | 1B, 7B | 3-stage training | Shown above |
Overview and Method
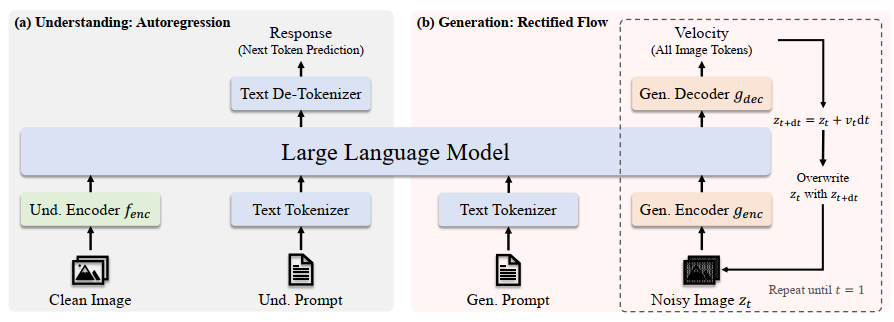
It’s kind of another branch of Janus but using diffusion technique to generate images.
Instead of the original diffusion process, they use rectified flow to iteratively transform a noise to a sample in the image distribution. The training objective is:
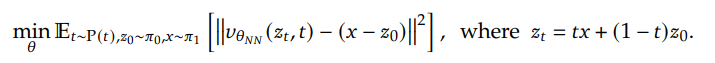
where $z_0$ is a sample from the standard Gaussian distribution, $v_{\theta NN}$ is a neutral network taking the point in the linear path from $z_0$ to $x$ and the time step $t$ as input, to predict the difference between $x$ and $z_0$.
If you don’t understand, Sec. 3.1 in this paper gives some good introduction then.
Based on that, the framework of JanusFlow is like:
The figure below gives a good illustration of the 3-stage training:
Three training objectives are used.
- Autoregression Objective
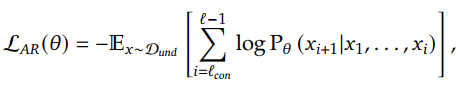
- Rectified Flow Objective
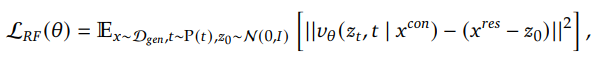
- Representation Alignment Regularization

02/04/2025 01:19
Maybe I need to go to sleep now.