ZeRO (DeepSpeed from Microsoft)
ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
paper (2019 arxiv, SC’20): https://arxiv.org/abs/1910.02054
website: https://www.deepspeed.ai/
Overivew of ZeRO optimizers
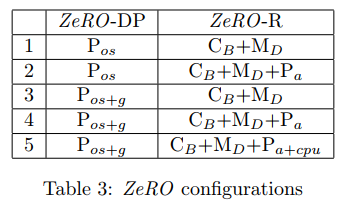
So basically, ZeRO has two sets of optimizations: ZeRO-DP to reduce the memory footprint along with data parallelism (like optimizer states by $P_{os}$, gradients by $P_g$, and parameters by $P_p$), and ZeRO-R to reduce the residual memory (like activations by $P_a$, temporary buffers by $C_B$, and memory fragementation by $M_D$). Particularly, activation are reduced along with model parallelism (I would say might be implemented as “sequence parallelism” in Megagron).
The highlight is that ZeRO-DP can significantly reduce the memory per GPU while keeping the communication overhead between GPUs unchanged when only applying DP alone (without the need of MP), therefore allow bigger models to train efficiently.
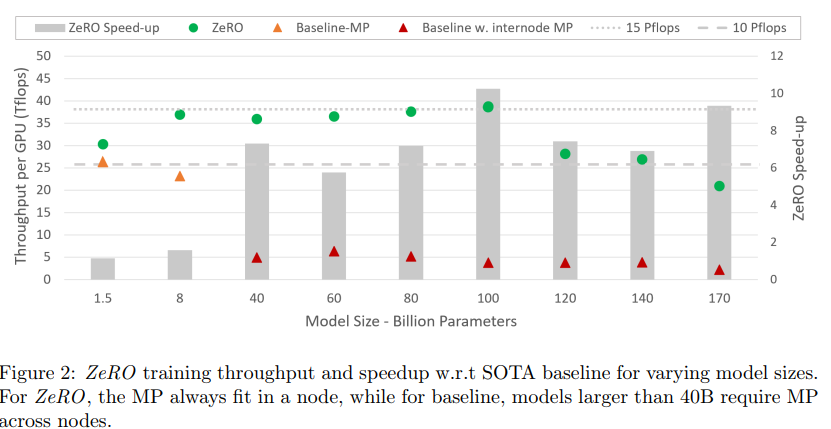
For example, as shown in above figure, Megagron-LM (which only applying tensor model parallelism here) will need to use multiple nodes because a single node (16 GPUs) cannot fit a bigger model (larger than 40B), causing inter-node communications that are very slow. However, for ZeRO, MP always fits in a node. Megatron make the computation granularity smaller (by splitting the model into smaller pieces) while ZeRO keeps every whole layer of transformer (my opinion). In addition, ZeRO also performs better than Megatron becuase the memory on each DP GPU is reduced without increasing communication overhead (as can be seen in the 1.5B case).
By adjusing the degree of ZeRO-DP, degree of MP, batch size, etc, ZeRO can gives good scalability for large models, even super-linear scalability:
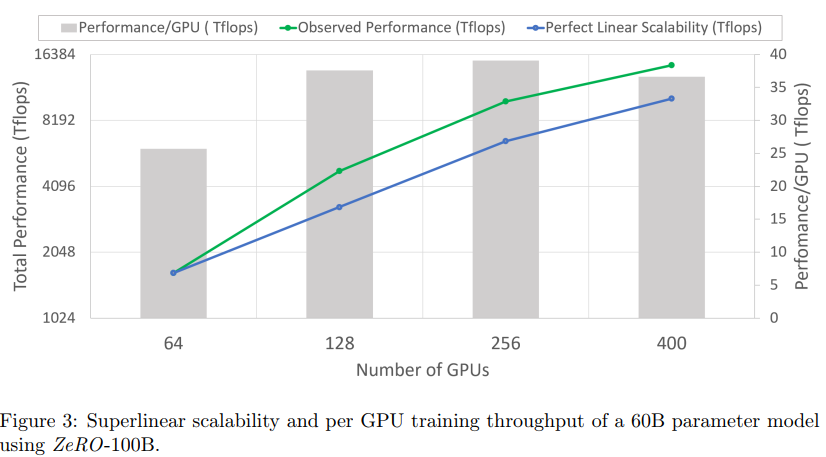
It is because $P{os+g}$ reduces per GPU memory consumption of ZeRO-100B with increase in DP degree, allowing ZeRO-100B to fit larger batch sizes per GPU, which in turn improves throughput as a result of increasing arithmetic intensity. For example, we assume MP is fit in a node with 16 GPUs, thus the degree of MP is bounded to 16, then the degree of DP can be increased with more GPUs.
So let’s describe more about the methods.
Let’s see which occupies the GPU memory during training
Let’s assume the training is via mixed precision (fp16/32) training where the parameters and gradients are stored in 16 bit (2bytes) while the optimizer states use 32-bit (4bytes). Let the number of parameters is $\Psi$ and Adam optimizer is used, then here is the memory consumption:
- Parameters: $2\Psi$
- Gradients: $2\Psi$
- Optimizer states: parameters + momentum + variance cuase $4\Psi + 4\Psi + 4\Psi = 12\Psi$
- Activations: It depends on the sequence length, batch size, and the structure of transformer models (please also see Megatron-LM series 3). For example, GPT-2 with 1.5B parameters, 1K sequence length, and batch size 32 causes 60G memory.
- Temporary buffers: Operations such as gradient all-reduce, or gradient norm computation tend to fuse all the gradients into a single flattened buffer before applying the operation in an effort to improve throughput.
- Memory fragmentation: It is caused by the interleaving between short lived and long lived memory objects. For example, the activations checkpointed (uisng activation checkpointing) lives longer than those need to be recomputed during forward pass. The gradients of parameters live longer than the gradients of activations during backward pass. A long contiguous memory will be fragmented into small pieces when the interleaved short memory has been released. So it will still possible to cause OOM error when the total available memory is larger than requested because of the lack of longer enough contiguous memory.
ZeRO-DP to reduce the first three memory parts (parameters, gradients, and optimizer states)
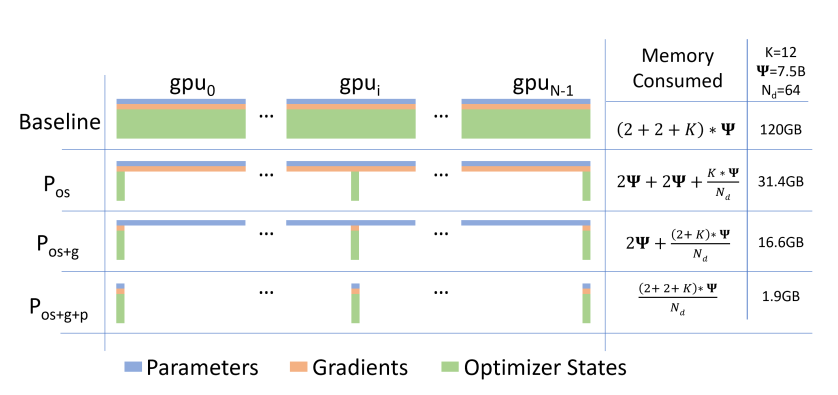
As shown in the above figure, ZeRO has three stages $P_{os}$, $P_{os+g}$, and $P{os+g+p}$ that gradually reduce the memory consumed per GPU ($N_d$ is the degree of data parallelism).
ZeRO-DP $P_{os}$
For $P_{os}$, the idea is quite simple. In this case, only the optimizer states are partioned to different DP GPUs, but all the parameters are replicated in each GPU. During forward and backward passes, the each DP GPU run for its own minibatch and get the loss via forward pass and gradient via backward pass. Then the gradients are kind of processed with “reduce-scatter” to the optimizers in each GPU (first reduce the gradients to calculate the average, and scatter the gradients to different pieces and give each GPU a piece). After that, each GPU run optimizer.step() to update the corresponding parameters. Finally, the “all-gather” operation is used to gather different pieces of updated parameters as the new parameters on each GPU.
Communication overhead
Compared with the original way of DP, the “reduce-scatter” and “all-gather” operations cause the same communication overhead as the “all-reduce” operation in the original DP.
ZeRO-DP $P_{os+g}$
For gradients, the forward pass is the same as above, but for the backward pass, whenever the gradients of a certain part of the parameters are calculated, use “reduction” operation for the gradients on different GPUs to get the average and store the average on the associated GPU only. After backward, each GPU has its own gradients part for a certain par of parameters, means the GPU can directly apply optimizer.step() to update those parameters. After tha, “all-gather” is used to update all parameters on each GPU.
Communication overhead
Put all the “reduction” operations together gives the same amount of communication as the “reduce-scatter” operation based on all gradient in $P_{os}$, plus “all-gather”, it give the same communication as the original DP.
ZeRO-DP $P_{os+g+p}$
Each DP GPU only store a certain part of parameters further. When the parameters outside of its partition are required for forward and backward propagation, they are received from the appropriate data parallel process through broadcast. The rest is the same as $P_{os+g}$.
Coummnication overhead
As stated by the authors, these extra broadcast operations cuases $1.5\times$ overhead compared with the previous two cases.
When $P_{os+g+p}$ is applied, the memory per GPU can be reduced by $N_d\times$, enabling very large models (1 trillion parameters) to fit in the GPU cluster with 1024 GPUs:
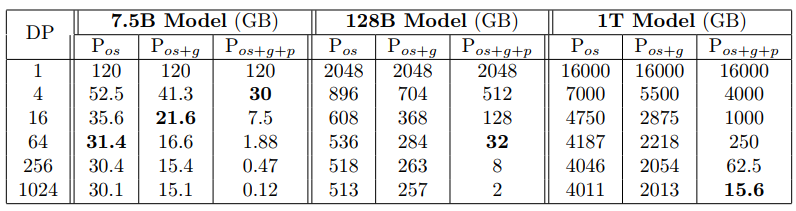
Here, with 1024 DP, each GPU only consumes 15.6 G memory for a 1 T model, which is lower than its limit (i.e., 32G for V100).
ZeRO-R to reduce residual memry
ZeRO-R $P_a$ and $P_{a+cpu}$
In my opinion, $P_a$ would be similar to sequence parallelism in Megatron-LM, but ZeRO might partition the activations along different dimensions along MP. Then $P_{a+cpu}$ additionally store the activations in CPU to free GPU memory.
ZeRO-R $C_B$ and $M_D$
For $C_B$, they simply use a performance-efficient constant-size fused buffer when the model becomes too large. For $M_D$, ZeRO does memory defragmentation on-the-fly by pre-allocating contiguous memory chunks for activation checkpoints and gradients, and copying them over to the pre-allocated memory as they are produced. MD not only enables ZeRO to train larger models with larger batch sizes, but also improves efficiency when training with limited memory.
Conlusion
ZeRO goes with DP, so from the perspective of model parameters, it doesn’t refactor the archiecture like MP. It can be combined with MP like Megatron to further scale the training while outperforming combining DP and MP alone.